3.3 Linux io_uring
随着硬件设备性能的发展,Linux 内核一个新的异步 IO 技术逐渐发展起来,io_uring。它总结了对 aio 的抱怨,发展成为一组真正异步、面向任何 IO 类型的异步接口 1。
io_uring 的使用可参考 Lord of the io_uring 系列文章。对于用户库,建议使用更加友好的 liburing。实际上有些 io_uring 的使用细节和文档,liburing 工程反而更加全面。
1 基本原理与基本接口
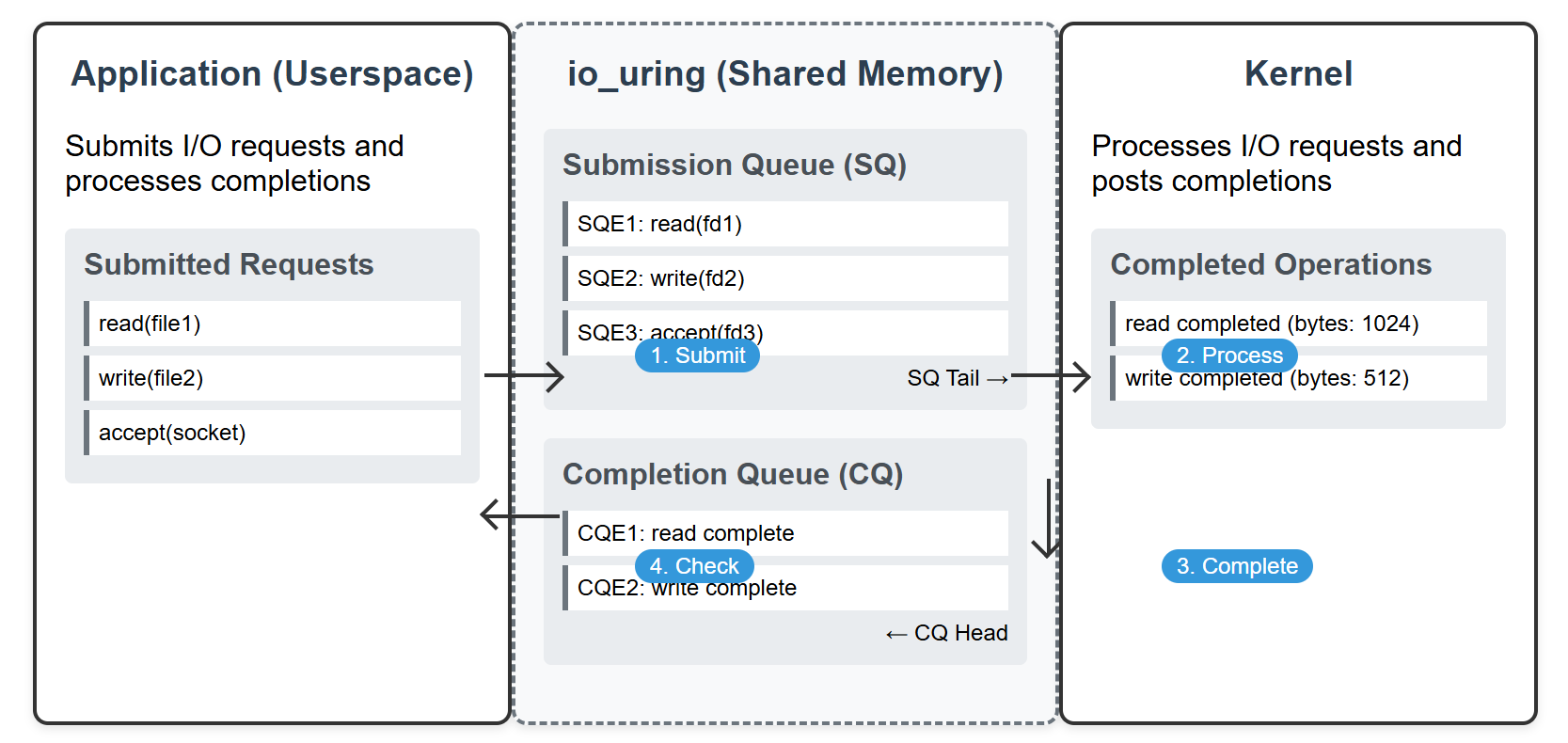
io_uring 使用的心智模型较为简洁,开发者可同样地理解为 “提交-执行-收割”。正如其名,分为两个环形队列
- 提交队列(SQ)用于提交请求,完成队列(CQ)用于通知请求完成情况
- 环形缓冲区在内核和用户空间共享
- 用户应用写入单个或者多个提交事件,包含了操作信息、数据指针等,提交到 SQ 尾部
- 用户应用使用系统调用提交请求
- 内核处理完毕后,将完成事件放到 CQ 尾部
- 用户应用从 CQ 头部读取完成事件
2 Ring! Ring! Ring! 环形缓冲区
无锁竞争 在单生产者-单消费者模型中,环形缓冲区是一个常见的高性能设计。在 io_uring 中:
- 提交队列(SQ):应用是生产者(提交IO请求),内核是消费者(消费请求)。
- 完成队列(CQ):内核是生产者(生成完成事件),应用是消费者(处理完成事件)。
使用环形缓冲区来消除锁竞争。通过分离生产者和消费者的指针(如头尾指针),双方无需共享锁,仅需内存屏障(Memory Barrier)保证可见性,大幅降低同步开销。
零拷贝 通过环形缓冲区,移动指针而不是数据复制。
延迟确定性 插入和删除操作在 O1 时间完成。
反压控制 生产者能感知缓冲区深度,在必要时候阻塞/丢弃数据。
3 io_depth
进入到异步 I/O 后,有一个重要的概念 io_depth 需要关注。读者可能已在硬盘性能测试套件 fio 中见过这类参数。借用 fio 手册的定义:
iodepth=int
Number of I/O units to keep in flight against the file即发出去正在执行的 io 数量。可以理解为生产-消费模型,我们提交一系列 IO 到异步队列中,这个 “深度” 指的就是我们视角提交出去,还未取得结果的 IO 数量。
为什么异步 I/O 才会关注 io_depth?
一般在同步 IO 中,每个线程同时只能提交一个 IO 请求,取得结果前线程被阻塞。因此同步 IO 的 io_depth 只能为 1。同步 IO 我们一般关注 in-flight 线程数量。
实际系统中,io_depth 可以作为观测系统压力的指标。观测到 io_depth 上升,意味着磁盘消费 IO 小于用户生产 IO 的速度,系统开始反压 (back pressure)。必须考虑引入合理的限流措施,并分析磁盘性能是否符合预期。
io_depth 越高越好吗?
在现代 SSD 硬件中,可以并行执行 IO 请求,因此适当的 io_depth (比如 16,64) 有利于充分利用磁盘性能。另外,OS 层面可以对 IO 进行一定合并,提升性能。
深度过大,效果提升逐渐不明显,一方面 OS 可能限制最大深度;磁盘达到性能极限后,也不会因为请求增大而大幅提升。
4 Code Snippet
我们重构上篇文章的线程池 IO 例程,改为使用 io_uring 方式提交 IO 请求、收割 IO 请求。
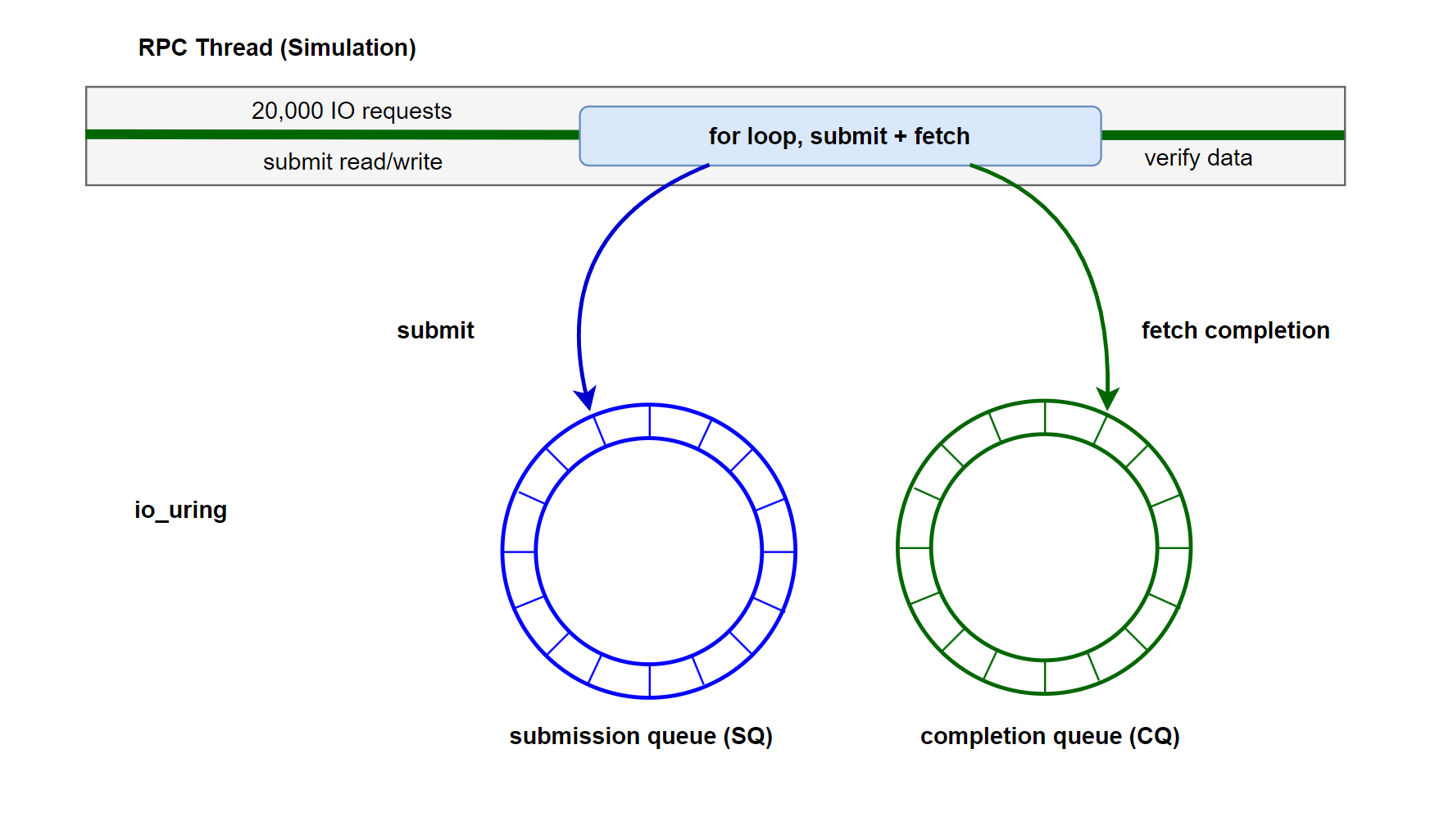
首先封装一些异步 IO 用的 context 结构体。
struct UringData {
void *user_ctx;
OpType op_type;
};
struct UserContext {
enum class Type { WRITE, READ } type;
int fd = -1;
off_t offset = -1;
std::shared_ptr<std::array<char, IO_BLOCK_SIZE>> buffer;
ssize_t write_result = -1;
ssize_t fsync_result = -1;
ssize_t read_result = -1;
bool write_completed = false;
bool fsync_completed = false;
bool read_completed = false;
UringData write_data{this, OpType::WRITE};
UringData fsync_data{this, OpType::FSYNC};
UringData read_data{this, OpType::READ};
};UringIO 类,模拟用户的 io 请求,异步 io 请求提交和收割。其中,我们将 write io 和 fsync link 到一起,保证逻辑顺序。
class UringIO {
public:
explicit UringIO(unsigned int depth) : ring_(), depth_(depth) {
int ret = io_uring_queue_init(depth, &ring_, 0);
if (ret < 0) {
throw std::runtime_error("io_uring_queue_init failed: " + std::string(strerror(-ret)));
}
}
~UringIO() { io_uring_queue_exit(&ring_); }
// simulate user io
void simulate_user_rpc(int fd) {
std::vector<std::unique_ptr<UserContext>> write_ctxs;
std::vector<std::unique_ptr<UserContext>> read_ctxs;
unsigned int inflight = 0;
int write_count = 0;
int read_count = 0;
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<> dis(0, IO_COUNT - 1);
auto start_time = std::chrono::high_resolution_clock::now();
// write: seq write + FSYNC
while (write_count < IO_COUNT || inflight > 0) {
// submit write
while (write_count < IO_COUNT && inflight <= depth_ - 2) {
auto ctx = std::make_unique<UserContext>();
ctx->type = UserContext::Type::WRITE;
ctx->fd = fd;
ctx->offset = write_count * IO_BLOCK_SIZE;
ctx->buffer = std::make_shared<std::array<char, IO_BLOCK_SIZE>>();
char content_char = 'A' + (write_count % 26);
memset(ctx->buffer->data(), content_char, IO_BLOCK_SIZE);
// get SQE for write
struct io_uring_sqe *write_sqe = io_uring_get_sqe(&ring_);
if (!write_sqe)
break;
io_uring_prep_write(write_sqe, fd, ctx->buffer->data(), IO_BLOCK_SIZE, ctx->offset);
io_uring_sqe_set_data(write_sqe, &ctx->write_data);
// get SQE for fsync
struct io_uring_sqe *fsync_sqe = io_uring_get_sqe(&ring_);
if (!fsync_sqe)
break;
io_uring_prep_fsync(fsync_sqe, fd, IORING_FSYNC_DATASYNC);
io_uring_sqe_set_data(fsync_sqe, &ctx->fsync_data);
fsync_sqe->flags |= IOSQE_IO_LINK; // link write+fsync
// submit
int ret = io_uring_submit(&ring_);
if (ret < 0) {
std::cerr << "io_uring_submit failed: " << strerror(-ret) << std::endl;
break;
}
inflight += 2;
write_ctxs.push_back(std::move(ctx));
write_count++;
}
// fetch competition
if (inflight > 0) {
struct io_uring_cqe *cqe;
int ret = io_uring_wait_cqe(&ring_, &cqe);
if (ret < 0) {
std::cerr << "io_uring_wait_cqe failed: " << strerror(-ret) << std::endl;
break;
}
UringData *data = static_cast<UringData *>(io_uring_cqe_get_data(cqe));
UserContext *ctx = static_cast<UserContext *>(data->user_ctx);
switch (data->op_type) {
case OpType::WRITE:
ctx->write_result = cqe->res;
ctx->write_completed = true;
break;
case OpType::FSYNC:
ctx->fsync_result = cqe->res;
ctx->fsync_completed = true;
break;
case OpType::READ:
ctx->read_result = cqe->res;
ctx->read_completed = true;
break;
}
io_uring_cqe_seen(&ring_, cqe);
inflight--;
}
}
// read: rand write
while (read_count < IO_COUNT || inflight > 0) {
// submit read
while (read_count < IO_COUNT && inflight < depth_) {
int block_num = dis(gen);
off_t offset = block_num * IO_BLOCK_SIZE;
auto ctx = std::make_unique<UserContext>();
ctx->type = UserContext::Type::READ;
ctx->fd = fd;
ctx->offset = offset;
ctx->buffer = std::make_shared<std::array<char, IO_BLOCK_SIZE>>();
struct io_uring_sqe *read_sqe = io_uring_get_sqe(&ring_);
if (!read_sqe)
break;
io_uring_prep_read(read_sqe, fd, ctx->buffer->data(), IO_BLOCK_SIZE, offset);
io_uring_sqe_set_data(read_sqe, &ctx->read_data);
int ret = io_uring_submit(&ring_);
if (ret < 0) {
std::cerr << "io_uring_submit failed: " << strerror(-ret) << std::endl;
break;
}
inflight++;
read_ctxs.push_back(std::move(ctx));
read_count++;
}
// fetch compelation
if (inflight > 0) {
struct io_uring_cqe *cqe;
int ret = io_uring_wait_cqe(&ring_, &cqe);
if (ret < 0) {
std::cerr << "io_uring_wait_cqe failed: " << strerror(-ret) << std::endl;
break;
}
UringData *data = static_cast<UringData *>(io_uring_cqe_get_data(cqe));
UserContext *ctx = static_cast<UserContext *>(data->user_ctx);
if (data->op_type == OpType::READ) {
ctx->read_result = cqe->res;
ctx->read_completed = true;
}
io_uring_cqe_seen(&ring_, cqe);
inflight--;
}
}
auto end_time = std::chrono::high_resolution_clock::now();
// verify data
bool write_all_success = true;
for (auto &ctx : write_ctxs) {
if (ctx->write_result != static_cast<ssize_t>(IO_BLOCK_SIZE)) {
write_all_success = false;
std::cerr << "Write failed at offset " << ctx->offset << ": expected "
<< IO_BLOCK_SIZE << ", got " << ctx->write_result << std::endl;
}
if (ctx->fsync_result != 0) {
write_all_success = false;
std::cerr << "Fsync failed at offset " << ctx->offset << ": "
<< strerror(-ctx->fsync_result) << std::endl;
}
}
bool read_all_success = true;
for (auto &ctx : read_ctxs) {
if (ctx->read_result != static_cast<ssize_t>(IO_BLOCK_SIZE)) {
read_all_success = false;
std::cerr << "Read failed at offset " << ctx->offset << ": expected "
<< IO_BLOCK_SIZE << ", got " << ctx->read_result << std::endl;
} else {
int block_num = ctx->offset / IO_BLOCK_SIZE;
char expected_char = 'A' + (block_num % 26);
for (size_t i = 0; i < IO_BLOCK_SIZE; ++i) {
if ((*ctx->buffer)[i] != expected_char) {
read_all_success = false;
std::cerr << "Data corruption at offset " << ctx->offset + i
<< ": expected " << expected_char << ", got " << (*ctx->buffer)[i]
<< std::endl;
break;
}
}
}
}
// statics
if (write_all_success && read_all_success) {
std::cout << "All IO operations completed successfully!" << std::endl;
std::cout << "Total IO operations: " << IO_COUNT * 2 << std::endl;
std::chrono::duration<double> elapsed = end_time - start_time;
std::cout << "Elapsed time: " << elapsed.count() << " seconds" << std::endl;
std::cout << "IOPS: " << static_cast<int>(IO_COUNT * 2 / elapsed.count()) << std::endl;
double throughput = (IO_COUNT * 2 * IO_BLOCK_SIZE) / (elapsed.count() * 1024 * 1024);
std::cout << "Throughput: " << throughput << " MB/s" << std::endl;
} else {
std::cout << "IO operations completed with errors" << std::endl;
}
}
private:
struct io_uring ring_;
unsigned int depth_;
};main 入口
int main(int argc, char *argv[]) {
const std::string test_file = "io_uring_test.bin";
unsigned int io_depth = 32;
if (argc > 1) {
try {
io_depth = std::stoul(argv[1]);
if (io_depth < 2) {
std::cerr << "IO depth must be at least 2, using default 32" << std::endl;
io_depth = 32;
}
} catch (const std::exception &e) {
std::cerr << "Invalid IO depth argument, using default 32: " << e.what() << std::endl;
}
}
std::cout << "Using IO depth: " << io_depth << std::endl;
int fd = open(test_file.c_str(), O_RDWR | O_CREAT | O_TRUNC, 0644);
if (fd == -1) {
std::cerr << "Failed to open file: " << strerror(errno) << std::endl;
return 1;
}
try {
UringIO uring_io(io_depth);
uring_io.simulate_user_rpc(fd);
} catch (const std::exception &e) {
std::cerr << "Error: " << e.what() << std::endl;
close(fd);
return 1;
}
close(fd);
return 0;
}5 运行结果与讨论
在上述程序中,我们故意设计了 4K 的顺序写 IO 模式。设置不同的深度,在一块 SATA SSD 上压测,结果如下。
| 队列深度 | 总操作数 | 耗时(秒) | IOPS | 吞吐量(MB/s) |
|---|---|---|---|---|
| 2 | 1,000,000 | 159.223 | 6,280 | 24.5332 |
| 4 | 1,000,000 | 81.0652 | 12,335 | 48.1865 |
| 8 | 1,000,000 | 71.1472 | 14,055 | 54.9038 |
| 16 | 1,000,000 | 67.4389 | 14,828 | 57.9228 |
| 32 | 1,000,000 | 63.9078 | 15,647 | 61.1233 |
| 64 | 1,000,000 | 53.269 | 18,772 | 73.3307 |
| 128 | 1,000,000 | 41.6389 | 24,016 | 93.8125 |
| 256 | 1,000,000 | 34.4474 | 29,029 | 113.397 |
| 512 | 1,000,000 | 33.1311 | 30,183 | 117.903 |
| 1024 | 1,000,000 | 30.0471 | 33,281 | 130.004 |
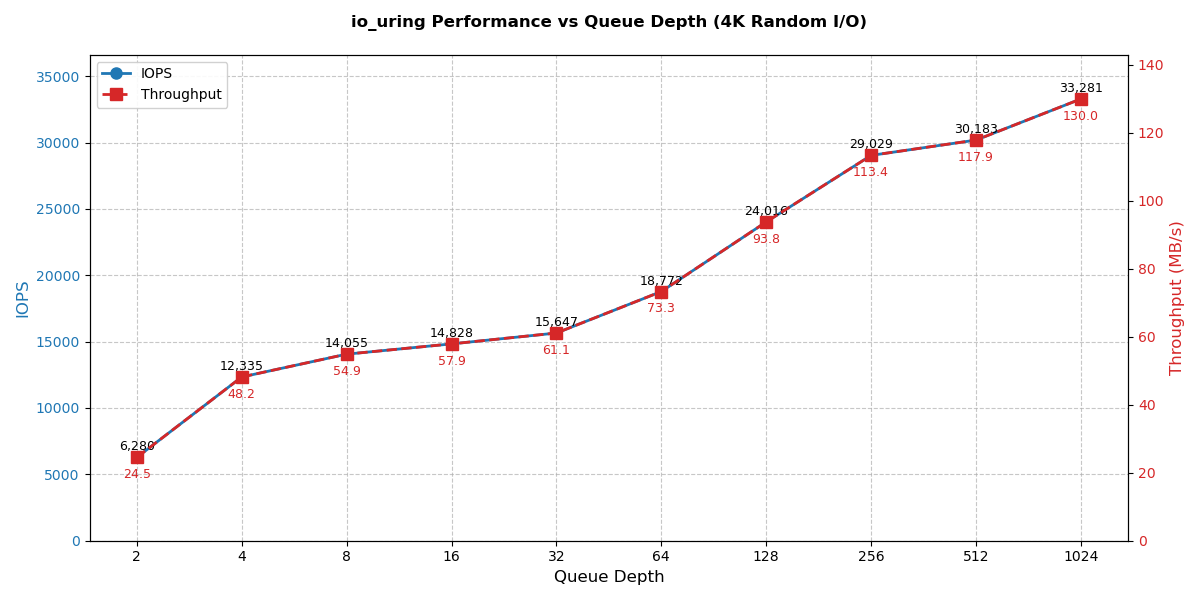
随着队列深度增加,IOPS持续提升(2→1024:6,280→33,281)。在128深度后提升幅度减小,512→1024 仅提升约 7%(图中 x 轴为 log 缩放)。我们的 4K 小 IO 顺序写,队列深度越大,系统的排队整流效应越好。
注意,这个例子只是为了简便,使用单线程操作 io,这不是必须的。设计者需要根据自己的需要合理安排线程模型(比如考虑使用的线程框架、rpc 框架,考虑 rpc+io 的 cpu 本地性等)。