4.1 混沌的分布式环境
引入: 分布式计算的谬误
有一组著名的断言,叫做分布式计算的谬误1,指出了新手容易作出的错误假设。
| No. | 断言 | |
|---|---|---|
| 1 | The network is reliable | 网络可靠 |
| 2 | Latency is zero | 延迟为零 |
| 3 | Bandwidth is infinite | 带宽是无限的 |
| 4 | The network is secure | 网络是安全的 |
| 5 | Topology doesn’t change | 拓扑不会改变 |
| 6 | There is one administrator | 有一个管理员 |
| 7 | Transport cost is zero | 运输成本为零 |
| 8 | The network is homogeneous | 网络是同质的 |
这些谬误断言,实际上也指出了分布式系统的重要特性:“失效” 是正常现象。
系统必须将失效作为一等功能去设计和实现。在实际生产工程中,开发者大部分的精力都在和 “失效容忍” 作斗争。
失效是正常的, 但需要建模和约束
虽然我们意识到失效是正常现象,但必须进行事前的建模和约束。下列失效故障的严重程度明显是不一致的:
- 单节点某一个硬盘读性能大幅度下降
- 单节点(18块硬盘)整机掉电
- 机架(10台节点)网络离线
- 整个机房因火灾掉电
而我们的方案的服务质量承诺 (SLA) 必须具有一个前提,比如
| SLA 要求 | 技术手段 |
|---|---|
| 单节点掉线仍然无损 | 使用共识算法保证多数派服务正常 |
| 容忍整个机房的掉线 | 需要两地三中心模式部署 |
不同失效的容忍要求,直接决定了系统的设计和实现,因此必须提前建好模型,定义故障边界。
系统永远不能保证容忍设计者没有考虑过的错误。
故障模型 (Failure Model)
故障模型用于描述系统能够容忍的抽象失效。在设计系统前,明确故障模型也非常重要。 文章2 很好地总结了几种常见的故障模型和应对手段。
| 故障失效模型 | 定义 | 特征 |
|---|---|---|
| Fail-stop Failures | 系统组件完全停止运行,其故障能立即被系统其他部分察觉,不再发送或接收消息 | - 组件停止且易检测 - 无部分故障或异常行为 - 适用于有故障转移机制的系统 |
| Crash Failures | 组件故障并停止运行,但故障可能不会立即被系统其他部分发现 | - 组件无声崩溃,不立即报警 - 需通过超时或通信错误检测 - 系统可能错误地继续与故障组件交互导致延迟 |
| Omission Failures | 系统组件未能发送或接收消息,可分为发送遗漏(组件未能发送消息)和接收遗漏(组件未能接收消息) | - 系统继续运行,但消息丢失或未送达 - 可能导致性能下降或数据过时 - 组件本身看似正常,难以检测 |
| Temporal Failures | 系统组件在预期时间框架外传递消息,导致性能下降或操作顺序错误 | - 组件发送或接收消息过早或过晚 - 可能导致数据不一致、竞争条件或同步问题 - 对延迟敏感的应用尤其脆弱 |
| Byzantine Failures | 组件行为不可预测或恶意,向系统不同部分发送冲突或错误数据 | - 组件可能行为不一致或恶意 - 故障不可预测,可能涉及损坏或伪造的消息 - 需要检测和缓解冲突状态 |
| Network Partitions | 组件间通信中断,但每个组件继续独立运行,可能导致“分裂大脑”场景 | - 组件独立运行,导致状态分歧 - 恢复复杂,尤其是在出现显著分歧时 |
| Arbitrary Failures | 由硬件问题、内存损坏或软件错误导致的不可预测故障,不遵循标准模式 | - 行为不稳定,难以重现 - 可能导致数据丢失或损坏 |
是否要考虑拜占庭问题?
拜占庭失效是指组件可能向系统不同部分发送冲突或错误数据。比如外部黑客的恶意数据。
一般在公司内网运行的服务,不考虑拜占庭问题。
公共服务,比如 ipfs、以太坊网络,必须要将拜占庭问题作为首要需求考虑。
单向联通的网络分区?
一般模型的 Network Partitions 是指网络的中断,包括发包和收包。单向联通常见于 iptable 的错误配置。在实际工程中,笔者会使用简单的拨测策略检测各节点中的网络情况。
磁盘故障模式
在存储领域,磁盘故障主要分为以下几种
| 磁盘故障类型 | 故障性质 | 处理措施 |
|---|---|---|
| 磁盘读写性能大幅下降 (Slow) | 临时故障或永久故障 | 隔离磁盘,降低磁盘读写权重 |
| 磁盘无响应 (Hang) | 永久故障 | 超时后隔离该磁盘,立即启动数据迁移 |
| 磁盘数据损坏 (EIO) | 永久故障 | 立即标记磁盘错误,立即启动数据迁移 |
进一步获取 kernel 日志,分析磁盘失效原因,预测磁盘故障是更佳的。
机械硬盘的故障率
机械硬盘的年故障率(Annualized Failure Rates, AFR)一般参考云存储服务商 Backblaze 发布的报告3。整体大致在 1% - 2% 左右,但不同品牌、型号差异较大。
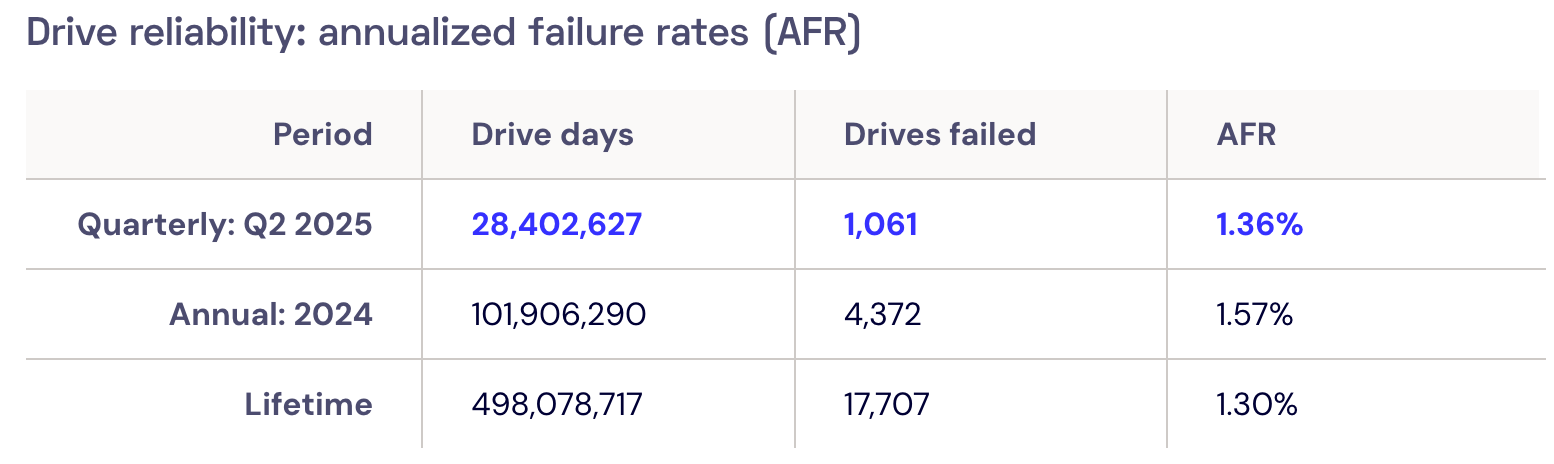
系统设计应至少满足该故障率的随机磁盘故障。实际还要要考虑整个节点的整体故障,因此系统应该容忍更高的故障率。
从运维视角思考
谬误断言中有一条叫做 There is one administrator (只有一个管理员)。笔者也是实际参与一些工作后体会到,整个方案的设计如何做到运维友好。
故障的处理、参数调控尽量做到简单有效。
若从运维同事的角度,下面哪个方案更容易接受呢?
| 对比维度 | 方案A(多参数手动配置) | 方案B(单参数自动调速) |
|---|---|---|
| 参数数量 | 5个(基础速率、时段系数、用户组权重等) | 1个(目标带宽占用率) |
| 配置方式 | 需在3个窗口手动填写,需校验参数关联性 | 单个窗口填写,系统自动处理细节 |
| 运维操作复杂度 | 高(需熟记参数依赖关系,多窗口切换) | 低(仅需设置核心目标,无需人工干预) |
| 故障处理方式 | 需人工分析参数配置是否冲突,手动调整多个参数 | 系统自动检测网络状态,自动回落至安全速率 |
| 对运维经验依赖度 | 高(依赖管理员个人知识储备) | 低(无需深入理解调速逻辑,傻瓜式操作) |
很显然是方案 B 更有持续性。
笔者曾经在某个系统中设计了类似 A 的方案,以求锦上添花的效果。但是方案不直观导致的中间沟通成本,交付消耗了大量的时间。
可观测性先行
近年来可观测技术已经成为事实标准,比如 Prometheus + Grafana、OpenTelemtry 等。
在系统初期,也应该在关键路径加入不同分位的观测指标,开发者应当对系统的瓶颈有很清晰的认识。尤其是分析性能问题时,极为有用。
整个分布式系统应当是个白盒模式,而不是黑盒+日志模式。
小结
本节从《分布式系统的几个谬误》出发,描述了笔者对于分布式环境的混沌性质的理解。
部分理论的认识确实是经过实践才能体会到,希望能和读者一同交流学习。