4.5 分布式存储形态与组件
前言
将规律抽象出来是困难的。尤其是超越了不同类型的分布式系统(数据库/存储/消息队列),在上层总结出的理论和经验。也是我们初看《DDIA》这本书时一头雾水的原因 —— 一旦超出了我们认知的具体用例,仿佛读到了什么,又仿佛什么都没读到。我们一定事先明确研究内容和背景,才能进一步讨论具体的设计思路、技术手法。
因此本节将重点讨论:
- 分布式存储系统的产品形态(对象存储、块存储、文件存储等)
- 分布式存储系统实现中的常见组件(存储引擎、元数据以及管理节点等)
- 针对一个假想的需求,一起思考、完成初步的技术选型 CheckList
本节目的:
- For 分布式存储开发者:为后续的分布式存储系统设计讨论,提供必要前提
- For 分布式存储用户:了解为什么某类存储产品有自己的优势和短板
- For 其他技术背景(比如分布式数据库)读者: 可将本节作为综述,了解分布式存储工程师的思维视角
分布式存储系统形态
随着大规模的使用和云服务的发展,自然形成了不同的产品形态,可分为对象存储、块存储、文件系统存储。
对象存储 (Object Stroage)
提到对象存储,我们一般认为 S3 已经成为了一种事实标准,任何一个提供对象存储语义的服务都不太可能绕过该用户接口。S3 的全称 Simple Storage Service,这个 Simple 到底 Simple 在哪里?
考虑一个大型互联网公司存储用户媒体数据的需求,这个数据可能有 1EiB 之巨。则此用户适合使用对象存储的理由如下:
Simple: 线性扩展和性能要求
- 集群存储 1TiB 和 1EiB,读写延迟数量级大致不变,都在百毫秒
- 集群存储 1TiB 和 1EiB,读写 iops 和带宽随着数据量线性增加
- 集群存储 1TiB 到 1EiB,扩缩容只需要提供机器资源即可,反之缩容即可
这种业务一般不会一根筋去死抠几百毫秒的延迟,但对集群的吞吐要求高,要求随着机器资源线性增长。大型集群应当支撑百万级别的并发。存储研发人员应重点保证系统性能的线性扩展。
Simple: 操作语义简单
这个 “语义简单” 是针对 Posix 文件系统的语义来讲的。此类业务一般对 Posix 的原子性放松很多 —— 重点支持 PUT/DEL 这种操作。
资源的上传和下载都可以直接通过 http + 互联网的方式进行。
另外,在对象存储中,对象名称是平铺的,使用 “/” 来模拟文件夹语义,实际上就是 k-v 语义,将用户的一整个对象名看做一个 key。用户使用文件夹语义做 ls 操作是根据 key prefix 模拟出来的。
比如对象所在 bucket: b1, 对象名: dir1/dir2/dir3/1.jpg。简单的 S3 对象存储会直接将 dir1/dir2/dir3/1.jpg 看做一整个 key。
Simple: 牺牲了文件夹语义(以及性能)
这种平铺的用户空间设计带来很好的扩展性和性能。代价是需要业务不能重度依赖 dir 语义,比如重度的 ls、rename、mv。而相当一些操作是不保证原子性的。
如用户使用 s3cmd 对对 dir 进行 du 和 ls,原理是进行 key-prefix 以模拟文件夹语义。在性能和计算消耗上,这和原生支持文件树数据结构的分布式文件存储系统无法相提并论。
这也是经常能看到由厂商将 S3 操作分为 A 类和 B 类,而定价不同1的有趣原因。
Simple: 不支持覆盖写
当一个对象成功写入后,其就是 immutable 的。用户无法对其中一块 range 的对象做覆盖写,这也是区别于文件系统的重要特性。
用户形态
S3 对象存储最适合存储巨量媒体数据的业务,或在 AI 训练中大量读取、写入 checkpoint 的场景,或大量的备份存储。它们对集群的可扩展、吞吐要求极高,而对 io 时延无极限要求。
当用户有覆盖写、大量的原子性 copy/rename,强依赖于文件夹操作时,平坦的对象存储显然无法适应其要求。
(有厂商支持部分文件树语义的对象存储形态,不过笔者认为其更像是一种支持部分 posix 语义的文件存储了)。
另外,进一步考虑多数据中心场景下的多活写入一致性问题,对象存储往往使用简单的最终胜出一致策略,或者干脆保留多版本。不涉及类似 kv 数据库的复杂一致性保证。
文件存储 (Filesystem)
分布式文件存储,也有称作 DFS、NAS 等简称。关键为用户提供了 POSIX 语义,可作为文件系统直接挂载操作。
用户形态
用户可能有万级别的容器同时挂载同一个文件存储的 Volume。可用于 AI 训练、容器内日志持久化、文件备份等。
FS: Posix 接口和文件树
分布式文件系统的语义类似于 Posix 和语义,一般提供兼容。其元数据的组织方式,在用户视角是文件-文件夹的树形结构,也就意味着文件夹的操作(比如 stat, rm, mv 等)是友好的。
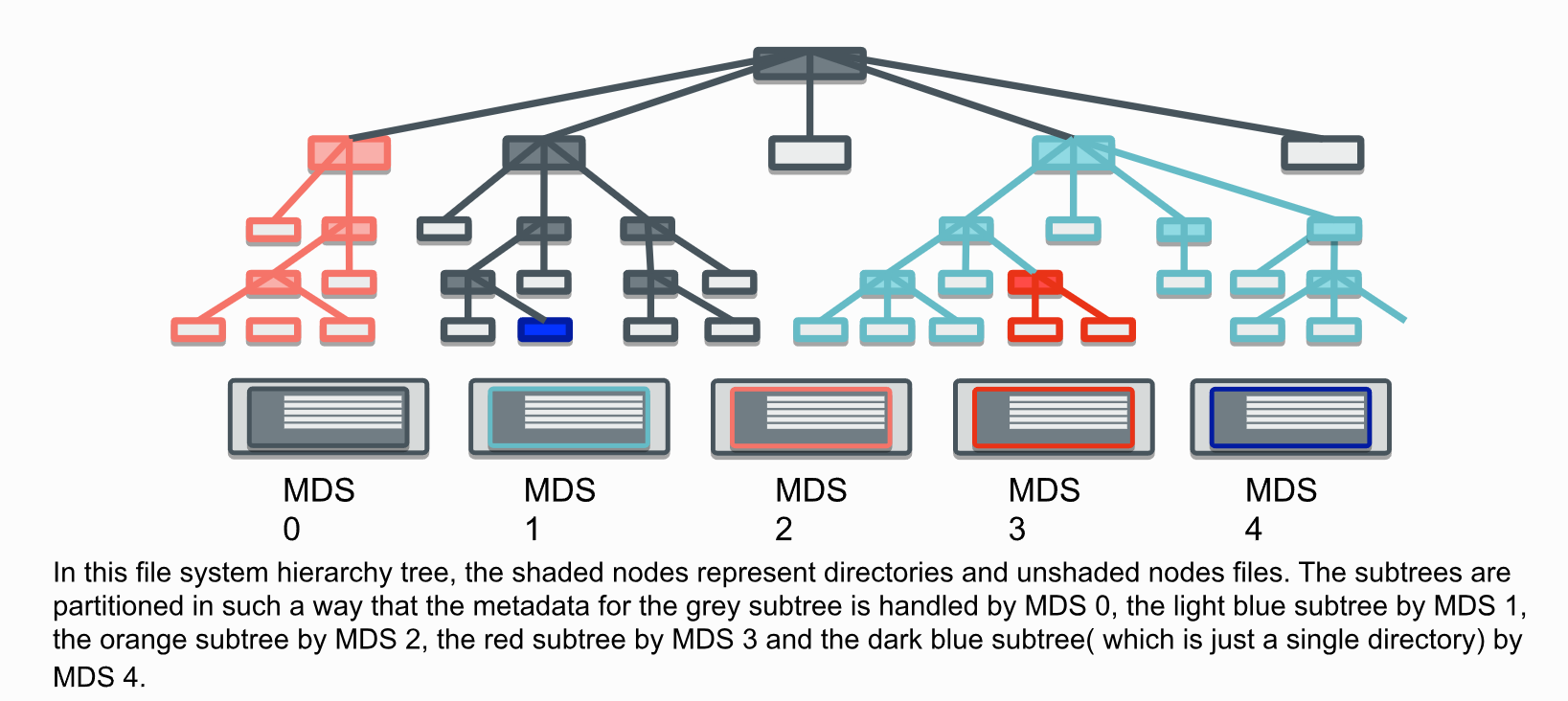
图: CephFS 元数据组织方式2,对用户是树形结构,内部为动态子树分区策略
Posix 语义的兼容性需要看具体的设计目标和文档。
FS: 一致性、并发保护和性能
一般可以得到的规律是,性能和严格的 Posix 原子性、一致性是天平的两端。这种系统为了提升并发性能,可能会放松一致性保证。反过来讲,一个提供严格的 posix 原子性和一致性的文件系统,势必会有大量的提交逻辑和补偿逻辑,牺牲性能。
牺牲一致性从而提升性能的手法有:
- 不支持多客户端 “并发写同一文件”,仅保证 “单写者 + 多读者” 的弱一致性
- 追加写场景:牺牲 “实时一致性”,仅保证 “最终一致性”
- 文件创建 / 删除场景:牺牲 “跨客户端即时一致性”,保证 “最终一致性”
- 副本写入场景:牺牲 “强原子性”,保证 “最终副本一致性”
等等。
块存储 (Block Storage)
块存储顾名思义,直接为用户提供一个块设备挂载到本地,像读写本地块设备一样操作远程存储。
和文件存储、对象存储最大的区别,是块存储服务直接提供一个线性 layout 空间,这里直接使用 CurveBS 块设备的布局映射3做演示。
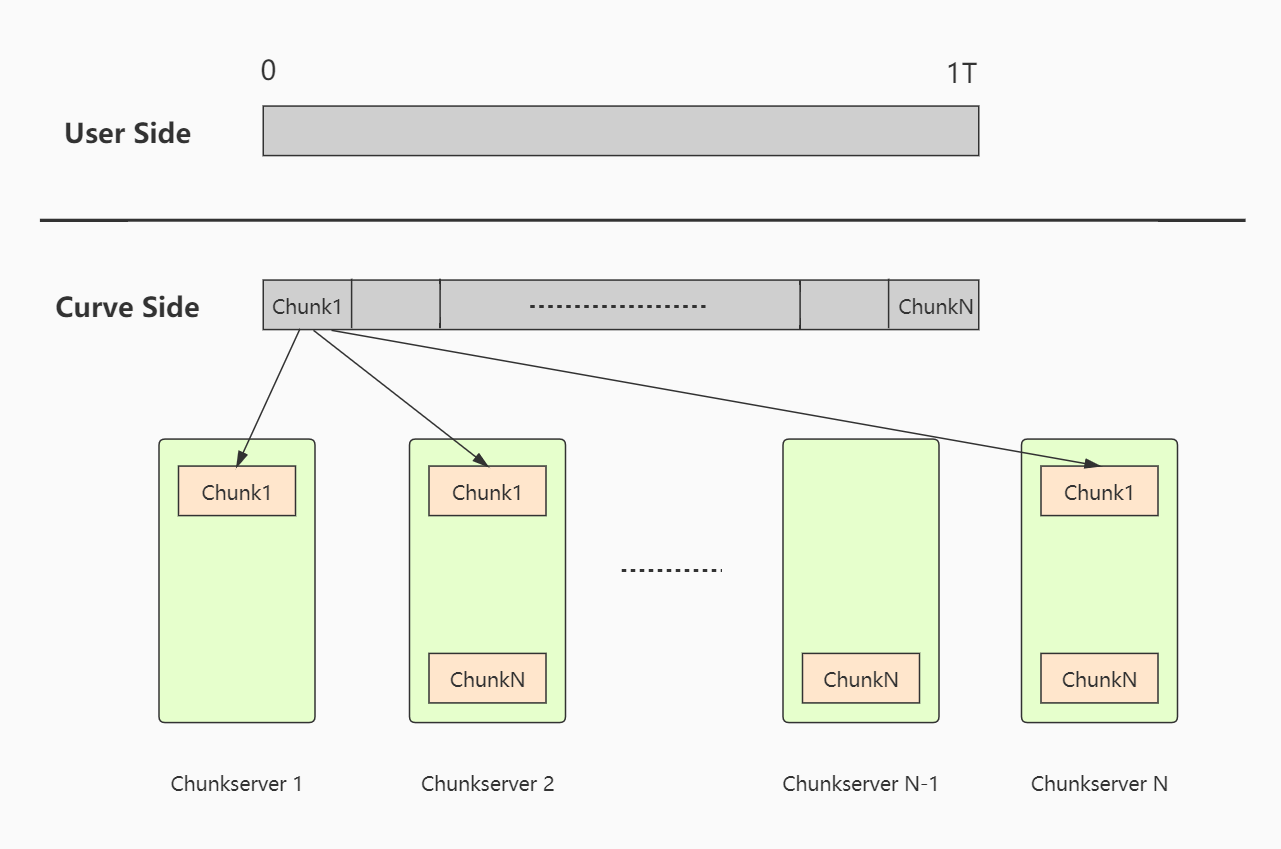
图: CurveBS 的块设备的布局映射3
则用户可以直接在上面格式化为自己的本地 FS,比如 ext4。而块设备服务不感知用户是如何管理自己 fs 元数据的,只是一个线性空间的块而已。
用户形态
块设备的用户往往直接将其作为 VM 系统盘、数据库的数据盘,因此对块设备的时延要求极高(us级别)、稳定性要求极高(P999不抖动等)。考虑数据库读写场景,用户一个同步 IO 被 hang 住,后续和正在进行的读写 IO 将直接掉底,就如同本地磁盘损坏、整个系统 hang 住一样。
用户一般不会去追求单个块设备的极致容量。一般在 GiB 和 TiB 级别。
性能级别
这里引用了阿里云 ESSD 系列块设备的服务指标4,读者可对其数量级有大概的感性认识:

使用成本
值得指出的是,块存储服务为了实现 us 级别的性能,几乎是无可选择地使用 RDMA 和 NVMe 技术,相比于 ms 级别的对象存储和文件存储,这一定意味着成本大幅提升。有一些批评者批评云厂商的块存储过于昂贵,本文不做讨论。但使用者一定要意识到块存储特点,选择适合自己服务的存储产品。
实际上,许多数仓分析、AI 训练等项目,混合使用了块存储(作为热点的高性能缓存) + 对象存储(冷数据, 量大管饱) 的混合存储模式,就是综合考虑了成本和性能,给出的工程解。例如 Alluxio5,将多种存储编排为统一的接口,成为了一种分布式存储的中间件。
小结
| 分布式存储形态 | 用户类型 | 核心优势 | IO 延迟 | 规模 |
|---|---|---|---|---|
| 对象存储 | 海量媒体数据、AI 训练、备份归档 | 线性扩展强(EiB 级)、成本低、高并发、互联网访问 | ms | EiB 级别 |
| 文件存储 | 容器共享、AI 训练、传统应用迁移 | 兼容 POSIX 语义、可直接挂载、支持文件树操作 | us 或 ms | TiB 级别 |
| 块存储 | VM 系统盘、数据库、高并发交易系统 | 微秒级时延、高 IOPS/高稳定性 | us | TiB 级别 |
分布式存储组件设计
我们已经了解了常见的产品形态,现在来了解另一个必要的前置知识:常见的分布式存储组件设计。
三大件:元数据、存储引擎和客户端
元数据和存储引擎的分层设计,常见于对象存储和文件存储产品形态中。有综述论文6描述了常见的分布式存储组件如下图。
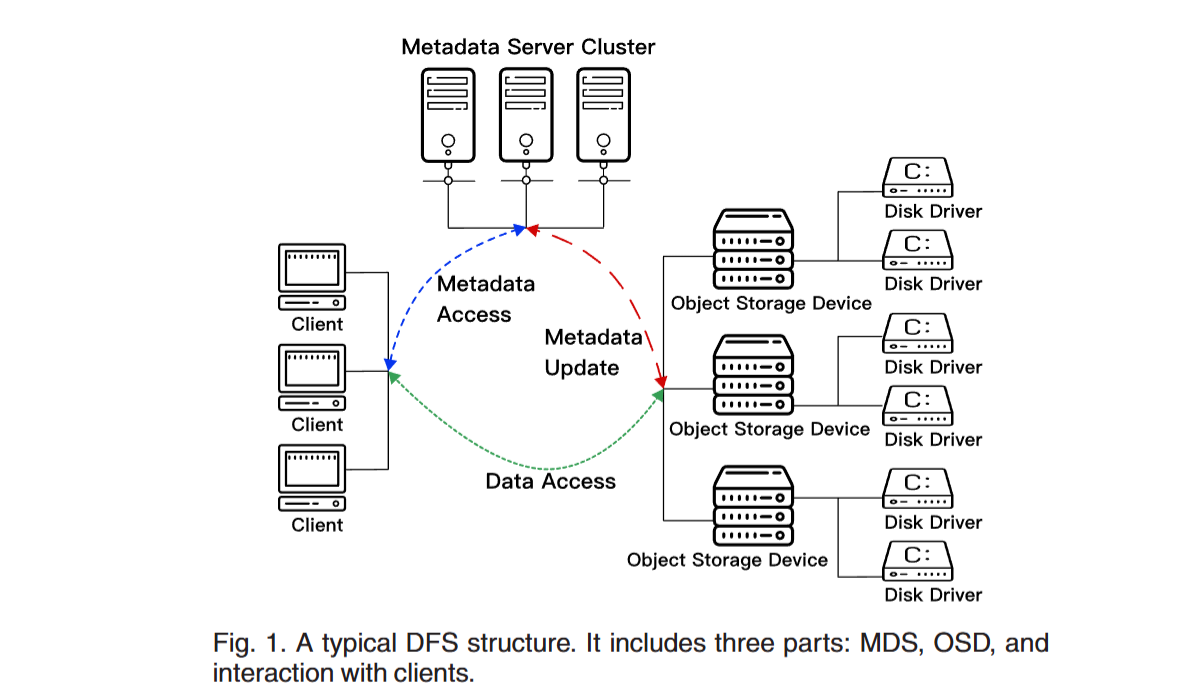
元数据组件
元数据顾名思义,存储着文件/对象的属性信息,以及它们到存储引擎上的映射。
大型分布式对象/文件集群需要动辄支撑千亿、万亿级别的元数据,一个重要的流派就是元数据管理逐渐独立出来,作为并行于存储引擎的组件。甚至直接使用 NoSQL 数据库,以得到近似线性的扩容支撑能力。
而块存储主要为用户提供块设备的线性空间,元数据管理的量级较小,一般使用单组高可用共识节点即可管理。
存储引擎
存储引擎把许多的存储节点、磁盘组织在一起,对上暴露存储的统一接口(PUT/DEL),对内负责数据的管理、路由和冗余修复等工作。
这种分层是容易理解的,因为上层逻辑(元数据层)根本不想了解数据是如何具体安置在磁盘上的,也不需要了解当一块磁盘损坏后,数据是如何被修复的。
另外,这种分层设计也有利于不同规模比例的部署,比如同样 10 PiB 的数据,可能是万亿级别,也可能是百万级别。逻辑分层有助于应对不同的集群规模,各自选择合适的物理资源分别部署元数据系统和存储引擎。
客户端组件
根据设计不同,客户端可以是轻量级,也可以是重量级的。
以块存储为例,Client 必须提供一些用于于 mount 的必要驱动,计算对应布局的映射,并需要处理后端少数磁盘故障的转移逻辑。而一个对象存储的 Client,也许只需要向可写冗余组写入对象、读取对象,这种设计逻辑简单的。
这三大件共同组成了分布式存储系统最常见的模型。比如我们看 CubeFS7,就是一个极为生动的例子:
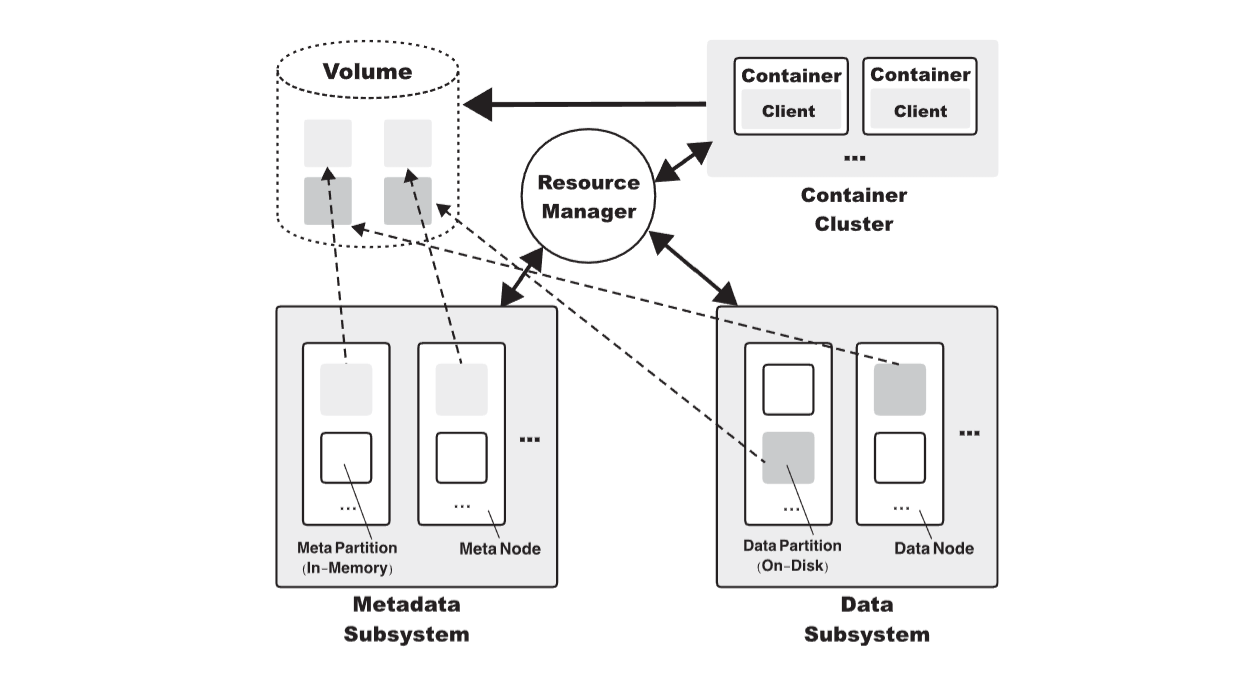
图:CubeFS7 的组件
-
H. Dai, Y. Wang, K. B. Kent, L. Zeng and C. Xu, “The State of the Art of Metadata Managements in Large-Scale Distributed File Systems — Scalability, Performance and Availability” in IEEE Transactions on Parallel and Distributed Systems, vol. 33, no. 12, pp. 3850-3869, 1 Dec. 2022, doi: 10.1109/TPDS.2022.3170574. ↩︎
-
Liu, Haifeng, et al. “Cfs: A distributed file system for large scale container platforms.” Proceedings of the 2019 International Conference on Management of Data. 2019. ↩︎ ↩︎