性能-成本-可靠性之不可能三角
成本优先与精益存储
分布式存储的成本始终是用户关注的重点之一。企业和用户在当今注重精益运营、降本增效的背景下,也越来越重视单位数据的存储成本。
比如,在所有需要持久存储的互联网媒体数据中,是不是也符合 28 定律,即 20% 的热数据占有了 80% 的访问量。再比如,某用户的读写模型都是纯写、几乎不读(合规存档目的)。针对这些数据特征,是不是仍有降低成本的空间?都是非常有实际意义的研究课题。
在当前分布式存储硬件背景下,性能 vs 成本 vs 数据安全性几乎成为了一个不可能的大三角。
用户永远是成本、性能、数据安全性都想要的。在满足性能需求前提下,针对用户实际需求,制定合适的数据放置和编码策略,需要存储开发者发挥专业技能,仔细斟酌了。
数据可靠魔法
复制:多个篮子,得加钱
保证数据可靠安全的秘诀是什么?非常简单,就是复制多份出去。正如老话所讲的 “鸡蛋不能放到同一个篮子中”。
既然单个数据可能随着硬盘爆炸、机器断电导致数据丢失,那只能是复制多份。但凡一份数据损坏,立即启动修复,趁着其他份还健康的时候赶紧恢复回来。
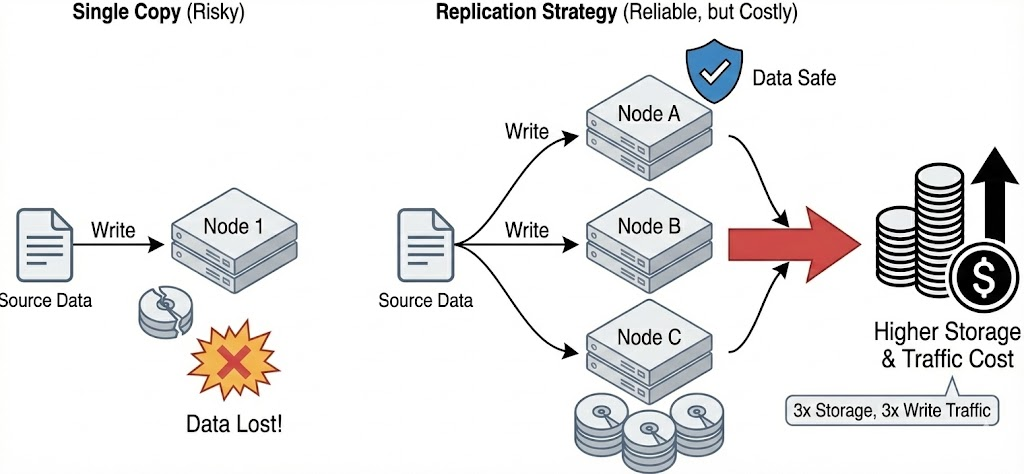
用户对于多份复制带来的成本是惊诧的。多份复制要有多份的写流量。后面提到的不同编码方式中,还可能影响到系统元数据的多次读写、用户读写性能的降低。但这些行为对大部分用户是透明的。
故障域:篮子不能放在同一辆板车上
单纯地多份复制不一定奏效,考虑同一个机房的同一个机架。这个机架上的两台机器,在火灾、断电、甚至仅仅是某台路由器故障时,大概率是“同生共死”的。如果多个副本放在同一个机架上,用户因数据丢失而红温的概率无疑会大大提高。因此,需要引入更上层的 “篮子划分”。
因此存储系统将故障域这个概念建立起来。根据故障域分配合适的数据复制存储位置,是现代分布式存储的必须能力之一。
在 Google 发布的关于分布式存储系统可用性论文1中,对故障级别进行如下的归类。
| 故障范围 | 基本概念 | 抵御故障手法 |
|---|---|---|
| Disk(磁盘) | 存储数据的基础硬件组件,负责永久存储数据,故障可能导致数据校验不匹配或永久性丢失 | 1. 背景清理进程(检测并处理校验不匹配的数据块);2. 客户端读取时验证数据完整性;3. 数据复制/纠删编码(Reed-Solomon)冗余备份 |
| Node(节点) | 运行存储服务器程序的物理机器,管理本地磁盘存储,故障多为暂时性(软件/硬件/网络问题等) | 1. 数据多副本或纠删编码分布在不同节点;2. 15分钟延迟恢复机制(避免 transient 故障无效恢复);3. 集群负载均衡与节点状态监控 |
| Rack(机架) | 集中部署的一组存储节点集合,共享网络交换机、电源电缆等基础设施,是核心故障域 | 1. 机架感知放置策略(同一数据条带的块不部署在同一机架);2. 跨机架数据复制;3. 独立机架电源/网络冗余设计 |
| Cell(存储单元) | 由数千个节点及上层协调进程组成的独立存储集群,通常部署在单一建筑/相邻建筑群 | 1. 多副本(R=2/3/4等)或纠删编码(RS(n,m))方案;2. 基于Markov模型的故障状态管理与优先级恢复;3. 故障爆发检测与批量恢复队列优化 |
| Datacenter(数据中心) | 存储Cell的物理部署载体,包含多个Cell,共享机房级电源、网络等基础设施 | 1. 多Cell跨数据中心复制(如R=3×2、RS(6,3)×3);2. 数据中心间独立基础设施(无共享故障点);3. 跨中心恢复带宽优化与按需数据恢复 |
该文章的年代较早(2010s),但仍然具有很大的参考意义。这种等级划分和实际基建设施的架构有关,比如有的云厂商提供的多可用区(AZ)2概念。核心的思路就是需要实际情况,在数据副本放置策略上尽量避开一损俱损。
值得指出的是,较远物理距离的复制(比如数据中心之间)天然带来了读写延迟增高的代价。存储开发者需要帮助用户做出合理选择。
例:经典的两地三中心架构
比如,当考虑到多个数据中心 + Rack 时候,一个可能的数据复制策略如下图所示。
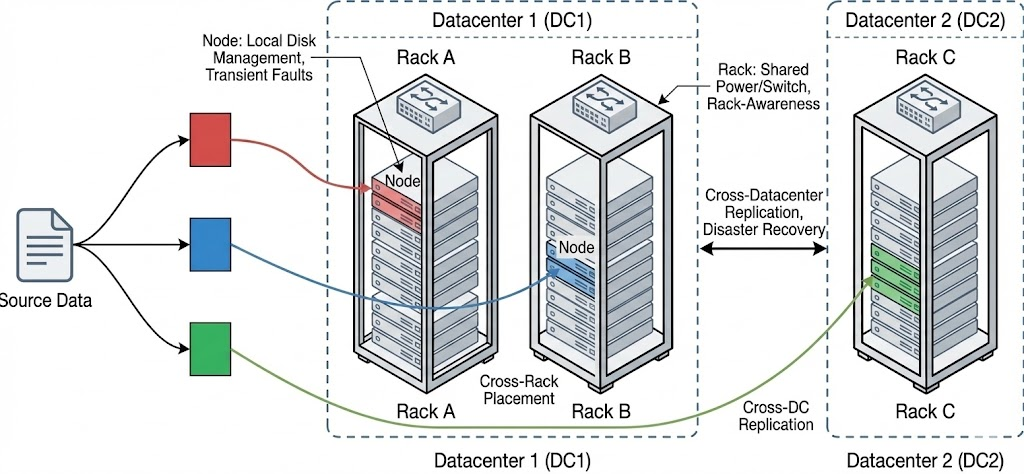
一个文件被复制成为了 3 副本,其中两份放在同一个数据中心的不同 Rack 上。一份通过异步备份,放在远端数据中心负责灾备。这就是最经典的两地三中心架构。
一旦涉及到这种跨地区的复制,将大大增加系统的成本性能负担。用户有必要明确,数据是否值得承担成本。
性能和成本魔法
沉迷于软件的分布式存储的开发者容易忘记近年来硬件性能质的飞跃。
笔者大概翻寻了从 2010 年至今的商用服务器主流规格,总结如下。看起来无论是 cpu 算力,还是网络带宽,每 5 年都会有一个大幅度飞跃。
| 时间节点 | CPU(型号/工艺/核心数) | 内存(规格/容量) | 网络(带宽/技术) | 存储(单盘容量/介质/接口/总容量) |
|---|---|---|---|---|
| 2010年 | Xeon 5500/5600;45/32nm;4-6核 | DDR3-1333;标配6-12GB,最大48-192GB | 1GbE为主,可选10GbE;无RDMA | 300-600GB;SAS HDD为主;SAS2.0/SATA3.0;总2.4-14.4TB |
| 2015年 | Xeon E5-2600 v3/v4;14nm;8-18核 | DDR4-2133/2400;标配16-64GB,最大512GB-1TB | 10GbE为主,可选25GbE;引入RDMA | 1-4TB;HDD为主,少量SATA SSD;SAS3.0/SATA3.0;总12-60TB |
| 2020年 | Xeon Gold 5200/6200;14nm;16-32核 | DDR4-2933;标配64-192GB,最大1-3TB | 25GbE为主,100GbE普及;支持RoCE v2 RDMA | 4-8TB HDD/0.96-3.2TB SSD;混合架构;NVMe1.3/SAS3.0;总48-358.4TB |
| 2025-2026年 | Xeon 6系列/EPYC 9005;7nm;64-192核 | DDR5-5600;标配192-512GB,最大8TB | 100GbE标配,200GbE普及;支持NVMe-oF/RDMA | 10-22TB HDD/30.72-245TB SSD;全闪存;NVMe Gen5/SAS4.0;总1.47PB-2.9PB |
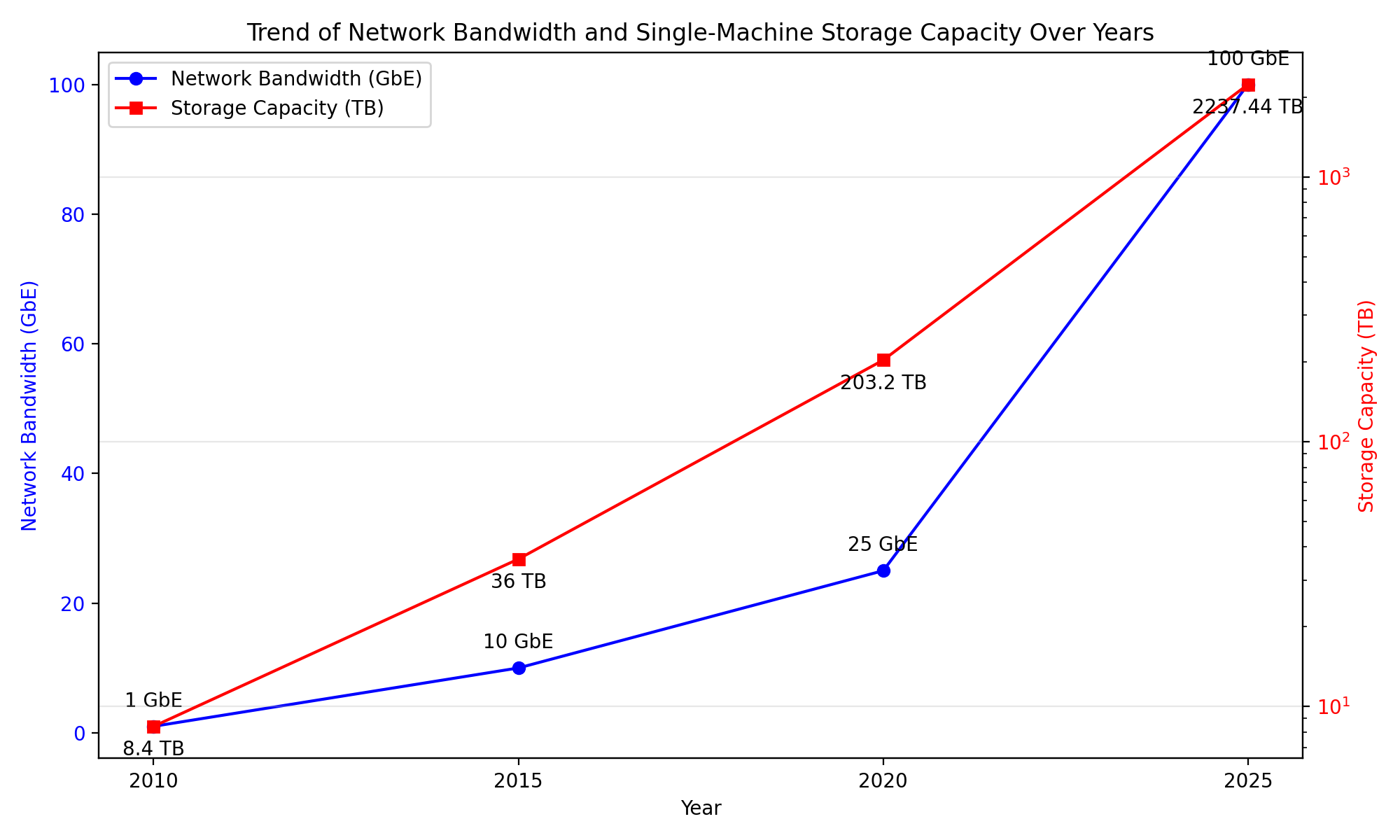
图:网卡和磁盘容量对比,注意磁盘容量坐标轴是指数级别。
- CPU:工艺从45nm迭代至7nm,核心数提升30倍+,新增AI加速与CXL互联能力,算力密度增加。
- 内存:从DDR3升级至DDR5,单台最大容量从192GB突破至8TB,带宽提升4倍+
- 网络:带宽从1GbE跃升至200GbE,RDMA技术普及。
- 存储:从机械硬盘主导转向全闪存,单盘容量提升400倍+,总容量从TB级突破至PB级。
硬件的发展直接将单机的极限性能推高一个数量级,导致可能本来需要分布式系统解决的问题,
密度和性能:水池变大了,但水管没变
存储有向全闪发展的趋势。不过当前来看,全闪集群的价格大大高于机械硬盘的集群。短期内更多是 HDD 和 SSD 的混合使用的折中,是一种成本上的妥协。
其中一个非常尴尬的事实是,SSD 随着技术发展,iops 和带宽大幅度提升。但 HDD 除了容量,iops 和顺序读写带宽基本在原地踏步,甚至由于密度增大而倒退。实属祖宗之法、不可变之!
笔者找了一些 10000 rpm 的企业级硬盘资料,最终汇总如下。
| 时间节点 | 单盘顺序读写带宽 | 随机读写IOPS | 单盘容量 | 说明 |
|---|---|---|---|---|
| 2010年 | 100-120 MB/s | 200-250 IOPS | 300-600GB | 接口以SATA 3.0(6Gb/s)、SAS 2.0(6Gb/s)为主,采用PMR技术,单碟容量约750GB;读取性能受接口带宽与磁密度限制,随机读取依赖16-64MB缓存支撑。 |
| 2015年 | 180-220 MB/s | 250-300 IOPS | 1-4TB | 接口升级至SAS 3.0(12Gb/s),缓存扩容至128MB,部分产品配eMLC闪存加速;单盘容量提升带动顺序读取增速,缓存优化使随机读取性能小幅提升约20%。 |
| 2020年 | 230-290 MB/s | 200-250 IOPS | 4-8TB | 单碟容量提升至1.6-1.8TB,缓存普遍为256MB;顺序读取受益于磁密度提升,随机读取受单盘容量增大导致的 IOPS 密度降低影响,性甚至能略有回落。 |
| 2025-2026年 | 250-300 MB/s | 180-220 IOPS | 10-22TB | 缓存维持512MB;顺序读取增速放缓(较2020年增幅约4%),受机械结构极限约束;随机读取性能持续小幅下滑,有逐步被 SSD 替代之趋势。 |
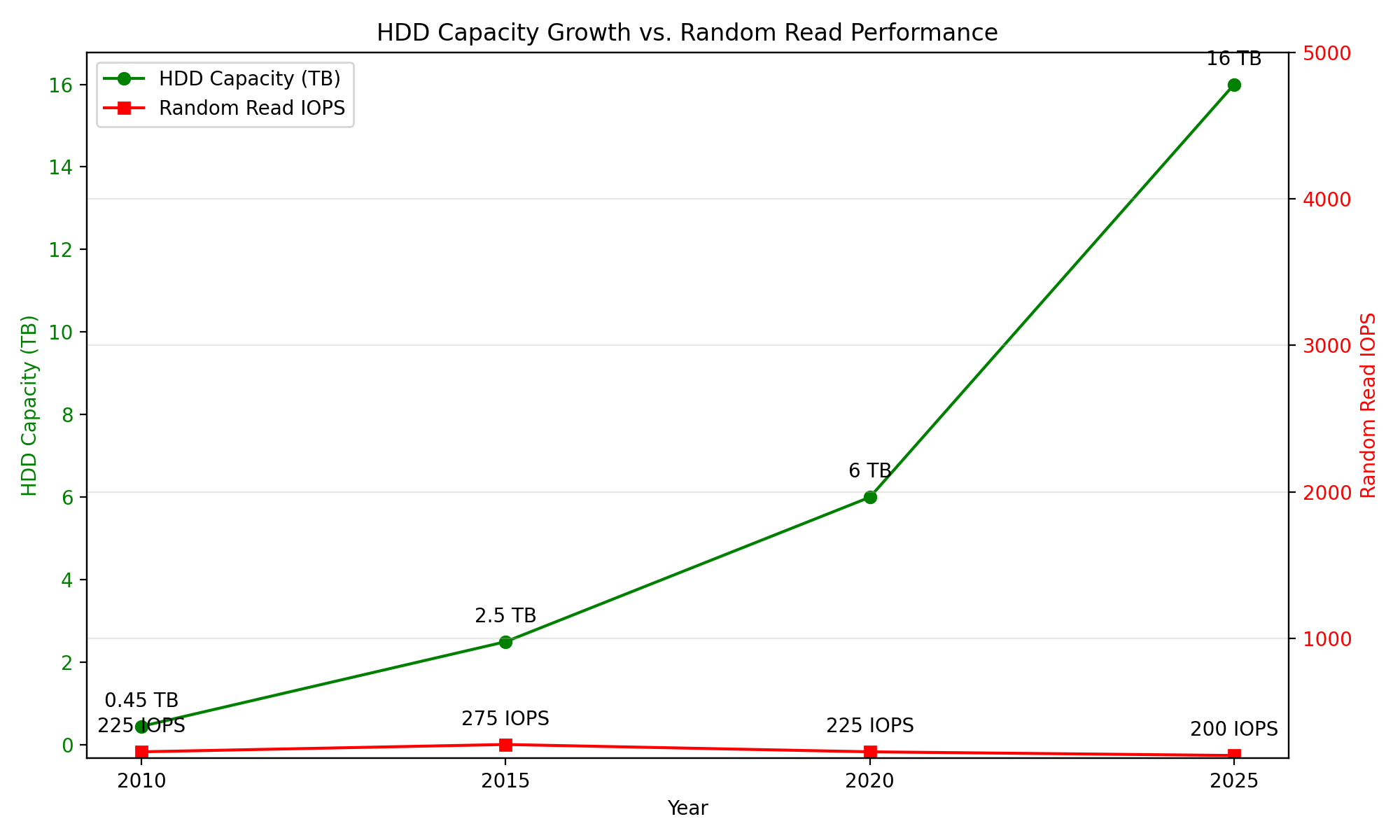
既然 SSD 这么好,HDD 甚至在开倒车,为什么不用全闪阵列呢?是有怀旧情怀不愿意用吗?没别的,太贵呗!
这意味这对于我们分布式存储开发者,当前阶段仍然手持两种性格鲜明的存储介质。
冷数据、旧机器与介质
数据是天然分冷热的,因此自然切合了不同硬件的特性。比如,我们可以利用 SSD+HDD 混合出下列工作情况。
SSD/HDD 直接划分存储池存储
将 SSD 集群和 HDD 集群直接作为两个逻辑集群,使用策略逐渐将冷数据转移到成本更低的集群中。好处是逻辑清晰,缺点是不容易榨干整个介质的读写潜力。
SSD 作为 HDD 集群的缓存介质
逻辑上是一整个集群,只是将读写热点数据放置于 SSD 中,同时所有的写操作也由 SSD 承接,从而规避了 HDD 孱弱的随机写性能。
旧机器利用
极少频率访问的数据,转移到旧机器组成的集群中,以减少成本。已经服役 N 年的机器,自然损坏概率是远远大于新机器的。需要仔细估算并观测旧机器损坏的频率。
还记得我们的数据修复逻辑吗?只要在最后一个副本损坏之前,将用户数据重新复制到预期的 N 份,就不会丢数据。因此要更激进地执行数据巡检和修复。
小结
有了足够的背景知识,我们就可以将分布式存储的问题抽象出来:就是在带宽和 iops 受限的多种介质上,排兵布阵,使用数据复制和数据编码手段满足成本-性能-可靠性的不可能三角。
(题外话:笔者最近听了一些 GPU 编排的技术讲座,也是在不同的算力芯片和内存容量带宽之间最大化榨干系统的能力。看来,大多数的工程问题都是殊途同归,只不过具体的技术手段不同。)
而攻克这不可能三角手段有哪些?其中一个重要的神兵利器,就是接下来的 “数据编码” 技术。
AI 辅助创作声明
- 复制配图和故障域的配图,由笔者文字详细描述,通过 Gemini 生成