2.2 直接 I/O (Direct I/O)
1 kernel page cache
在了解 Direct I/O 之前,比如先了解下 “不直接” IO 是什么东西。Page Cache 是内核用于优化 I/O 性能的重要机制。它们通过减少磁盘访问次数、加速数据读写,显著提升系统整体性能。
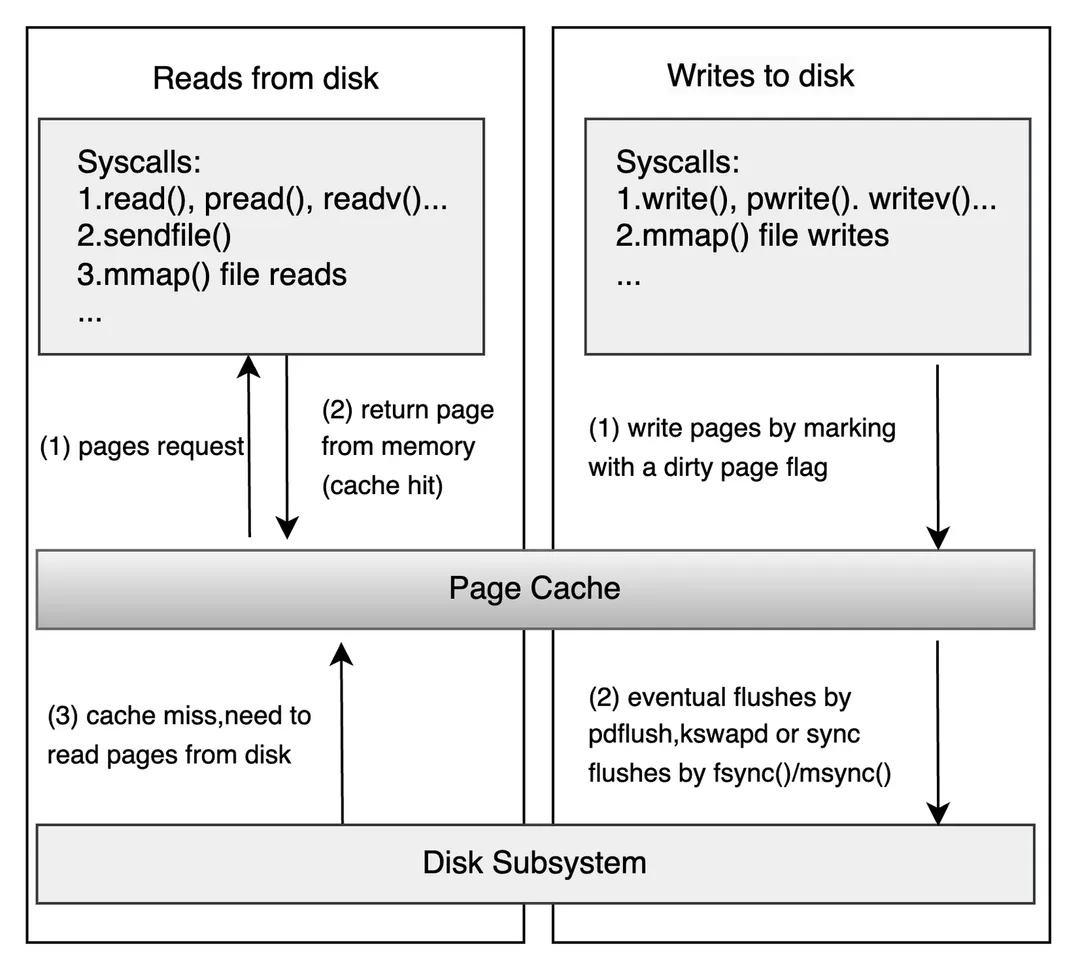 图:Page Cache 层示意图 1
图:Page Cache 层示意图 1
当我们直接打开一个普通文件不设置 O_DIRECT 时,所有的读写默认经过 Page Cache。(有例外是某些直接设备打开会自带 DIRECT 属性,我们这里不去深究,聚焦于本地磁盘普通文件。)
// 使用 bufferd I/O
int fd = open("testfile.txt", O_RDWR | O_CREAT, 0644);2 基本使用
man 中向我们很好地描述了 DIRECT 的用法和注意事项。
O_DIRECT (since Linux 2.4.10)
Try to minimize cache effects of the I/O to and from this file. In general this will degrade perfor‐
mance, but it is useful in special situations, such as when applications do their own caching. File
I/O is done directly to/from user-space buffers. The O_DIRECT flag on its own makes an effort to
transfer data synchronously, but does not give the guarantees of the O_SYNC flag that data and neces‐
sary metadata are transferred. To guarantee synchronous I/O, O_SYNC must be used in addition to
O_DIRECT. See NOTES below for further discussion.
A semantically similar (but deprecated) interface for block devices is described in raw(8).O_DIRECT 尝试最小化文件 I/O 的缓存效应,数据直接在用户空间缓冲区和存储设备之间传输,绕过内核页缓存。适用于需要自行管理缓存的应用程序(如数据库),但通常会导致性能下降。默认会尽力同步传输数据,但不保证数据和元数据的完整同步(需配合 O_SYNC 实现严格同步)。
限制:
对于开发者,最大的限制就是读写文件时,地址、长度和文件偏移必须满足对齐要求(通常是文件系统块大小的倍数,如 4KB)。一些文件系统 (比如 XFS) 和高版本的内核可能放宽到 512B 的对齐 2。手册中提到可以使用 ioctl(2) 的 BLKSSZGET 操作获取边界 2。对应的 shell 操作为
blockdev --getss对齐的内存可以使用 posix_memalign 申请
void* aligned_alloc(size_t size) {
void* ptr = nullptr;
if (posix_memalign(&ptr, PAGE_SIZE, size) != 0) {
perror("posix_memalign failed");
exit(EXIT_FAILURE);
}
return ptr;
}一般来讲,4KiB 是最常见的对齐 size。我们开发系统时候,需要在目标环境进行充分测试。
3 Code Snippet
#include <iostream>
#include <fcntl.h>
#include <unistd.h>
#include <cstdlib>
#include <cstring>
#include <sys/stat.h>
#include <sys/types.h>
// 获取系统页面大小(通常为4096字节)
const size_t PAGE_SIZE = sysconf(_SC_PAGESIZE);
// 分配对齐的内存
void* aligned_alloc(size_t size) {
void* ptr = nullptr;
if (posix_memalign(&ptr, PAGE_SIZE, size) != 0) {
perror("posix_memalign failed");
exit(EXIT_FAILURE);
}
return ptr;
}
int main() {
const char* filename = "direct_io_example.bin";
const size_t file_size = PAGE_SIZE * 4; // 4页大小
const int flags = O_RDWR | O_CREAT | O_DIRECT;
const mode_t mode = S_IRUSR | S_IWUSR; // 用户读写权限
// 1. 打开文件(使用O_DIRECT标志)
int fd = open(filename, flags, mode);
if (fd == -1) {
perror("open failed");
exit(EXIT_FAILURE);
}
// 2. 分配对齐的内存缓冲区
char* write_buf = static_cast<char*>(aligned_alloc(file_size));
char* read_buf = static_cast<char*>(aligned_alloc(file_size));
// 3. 准备写入数据
const char* message = "Hello, Direct I/O World!";
strncpy(write_buf, message, strlen(message));
std::cout << "Writing data: " << message << std::endl;
// 4. 写入文件(必须对齐的写入)
ssize_t bytes_written = write(fd, write_buf, file_size);
if (bytes_written == -1) {
perror("write failed");
close(fd);
free(write_buf);
free(read_buf);
exit(EXIT_FAILURE);
}
std::cout << "Wrote " << bytes_written << " bytes" << std::endl;
// 5. 将文件指针重置到开头
if (lseek(fd, 0, SEEK_SET) == -1) {
perror("lseek failed");
close(fd);
free(write_buf);
free(read_buf);
exit(EXIT_FAILURE);
}
// 6. 读取文件
ssize_t bytes_read = read(fd, read_buf, file_size);
if (bytes_read == -1) {
perror("read failed");
close(fd);
free(write_buf);
free(read_buf);
exit(EXIT_FAILURE);
}
std::cout << "Read " << bytes_read << " bytes" << std::endl;
std::cout << "Data read: " << read_buf << std::endl;
// 7. 清理资源
close(fd);
free(write_buf);
free(read_buf);
// 删除测试文件
unlink(filename);
return 0;
}运行一下
➜ snip git:(master) ✗ g++ -Wall -Wextra -g -o 02 ./02_direct_io.cpp
➜ snip git:(master) ✗ ./02
Writing data: Hello, Direct I/O World!
Wrote 16384 bytes
Read 16384 bytes
Data read: Hello, Direct I/O World!4 为什么 Direct IO 有对齐要求?
现代存储设备(如 HDD、SSD、NVMe)的 I/O 操作通常以固定大小的块(通常为 512B、4KB 等)为单位进行,这是硬件设计的基本约束。
当使用 O_DIRECT 时,数据直接在用户空间缓冲区和存储设备之间传输(通过 DMA),而 DMA 控制器对内存访问有以下要求:
- 内存对齐:DMA 控制器通常需要缓冲区地址对齐到块大小边界(如 4KB),否则无法高效操作。
- 传输块大小:DMA 传输的字节数必须是块大小的整数倍,否则硬件无法处理。
即使我们不使用 O_DIRECT,内核通的页面缓存(Page Cache)和 I/O 调度器也要将用户空间的非对齐请求转换为硬件兼容的对齐操作。此时针对某个 4KiB 页的一部分并发读写,也可能遇到奇怪的问题。
5 为什么数据库引擎喜欢 Direct IO?
5.1 自行优化读取策略
数据库引擎往往自己需要实现内存缓存机制。如果仍然使用 page cache,将导致多一份内存缓存,效率不佳。
使用 page cache 时,kernel 提供了一些 hint 来提示用户的读写模式。用户可以使用 fadvise 来提示自己的读写模式。
int fd = open("large_file.bin", O_RDONLY);
posix_fadvise(fd, 0, 0, POSIX_FADV_SEQUENTIAL); // 提示顺序访问
// ... 读取文件
close(fd);内核会根据提示做一些预读 (readahead) 等操作。这些操作经过用户层的自行实现后,就没有必要了。另外用户层针对自己模式的优化性能天花板会比内核的通用高。
5.2 可预测的性能
避免内核做其他优化,有助于开发者根据磁盘的负载准确预计压力。每个请求也不会因为内存淘汰、sync 刷盘有较大的波动。
存储开发者处理前台用户写入时,更喜欢稳定可预测的性能,反而不是 boost 一个高峰然后反复波动的性能。
6 fsync 性能
要求数据写入即落盘的存储引擎 (比如写 raft log)应特别关注硬件 fsync 性能。存储引擎的日志系统一般对 fsync 的性能要求高,因为必须要等待成功落盘持久化才能进行下一步操作。文章 3 提到一个小技巧,可以把 WAL 和其他内容分离。日志专门写在 fsync 性能高的介质(一般这种介质比如傲腾的容量偏小),而其他持久化内容可以写在普通介质上。
有几个比较有趣的现象:
- 企业级的存储硬件,往往 fsync 性能远远高于消费级硬件3。
- raid 卡如果提供了非易失性缓存,对小型 io 性能有提升。硬件缓存做了一层写流量的整形。
7 一些讨论
7.1 一定首选 O_DIRECT 吗?
笔者认为不是这样的。一般看系统的需求和阶段。如果用较少的工作量就能满足需求,系统的内存较为充足,那么使用 Page Cache 绝对是性价比最高的选项。
系统当然可以先实现为默认 4KiB 对齐,后续遇到性能瓶颈再自行设计内存缓存策略。
7.2 使用 O_DIRECT 后还需要 O_SYNC 吗?
手册 2 明确描述:默认会尽力同步传输数据,但不保证数据和元数据的完整同步(需配合 O_SYNC 实现严格落盘数据安全性保证)。
7.3 O_DIRECT / O_SYNC / Sync IO 傻傻分不清?
笔者这里多啰嗦一句,Sync 翻译为 “同步”,在新手开发者入门时确实容易感到歧义。其实只要理解了他们的含义后就非常明确:两者完全不是一个概念。
O_SYNC是指数据被刷到稳定介质上,是数据安全性的 “刷盘”。打开文件时候设置这个 FLAG 即可。Sync I/O则是指这个 IO 调用会不会阻塞进程。进程需要 “同步” 等待操作完成才能返回继续运行。