2.4 线程池模式 (Thread Pool)
1 动机
在上文中,我们已经意识到了 Sync IO 调用会阻塞我们的线程。这期间对 CPU 反而是闲置,这就是我们常说的 I/O 密集任务。(另一个反面是计算密集型任务,会持续占用 CPU 进行有效计算。)
这种线程闲置也会导致同时提交到存储硬件的 IO 操作变少,很难榨干存储硬件能力,尤其是 SSD 介质。
因此,一种自然而然的模式就应运而生了。既然阻塞一个线程,那我们就用一组线程,提高整体的并发 —— 将所有同步 IO 交由一组线程执行。
接下来我们实现一个示例程序作为演示,包含 1 组 IO 线程,还有额外 1 个线程模拟用户的 rpc 读写逻辑。
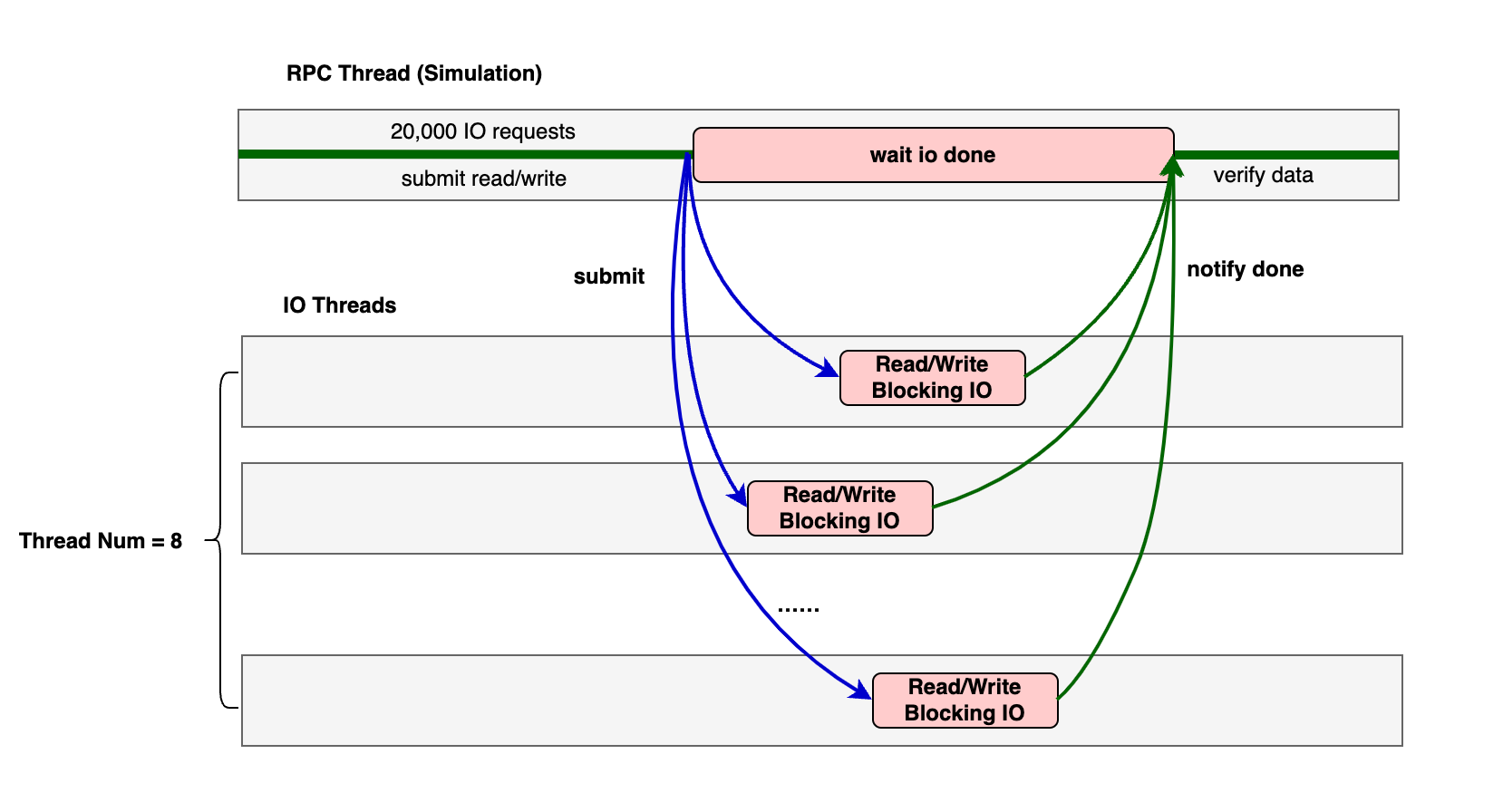
图: 示例程序的线程分工
2 Code Snippet
2.1 简单的线程池实现
我们新建一个 IOThreadPool 类,构造时使用 std::thread 创建线程。RPC 模拟线程可以通过 enqueue 提交任务函数进入队列。工作线程从队列里取出任务并执行。
class IOThreadPool {
public:
explicit IOThreadPool(size_t num_threads) : stop(false) {
for (size_t i = 0; i < num_threads; ++i) {
// create worker thread
workers.emplace_back([this] {
// worker loop
while (true) {
std::function<void()> task;
// fetch task
{
std::unique_lock<std::mutex> lock(this->queue_mutex);
this->condition.wait(lock,
[this] { return this->stop || !this->tasks.empty(); });
if (this->stop && this->tasks.empty())
return;
task = std::move(this->tasks.front());
this->tasks.pop();
}
// do task
task();
}
});
}
}
void enqueue(std::function<void()> task) {
{
std::unique_lock<std::mutex> lock(queue_mutex);
if (stop) {
throw std::runtime_error("enqueue on stopped ThreadPool");
}
tasks.push(task);
}
condition.notify_one();
}
~IOThreadPool() {
{
std::unique_lock<std::mutex> lock(queue_mutex);
stop = true;
}
condition.notify_all();
for (std::thread &worker : workers) {
worker.join();
}
}
private:
std::vector<std::thread> workers;
std::queue<std::function<void()>> tasks;
std::mutex queue_mutex;
std::condition_variable condition;
std::atomic<bool> stop;
};2.2 模拟用户 rpc 线程
创建一个线程来模拟用户读写的 rpc 执行。这里我们处理内存,提交 IO 任务,等待所有 IO 执行完成,最终进行数据验证。
这里我直接提交了 lambda 函数。由 IO Thread Pool 工作进程执行。lambda 函数内的 IO 操作完成后,设置同步原语标记这笔 IO 完成。
注意:我在写操作使用了 fsync 保证数据安全性。这将导致 IO 阻塞时间变长,以突出 IO 线程池的效果。
void simulate_user_rpc(IOThreadPool &pool, int fd) {
std::vector<std::shared_ptr<IOResult>> write_results;
auto start_time = std::chrono::high_resolution_clock::now();
// sequential write
for (int i = 0; i < IO_COUNT; ++i) {
auto write_buf = std::make_shared<std::array<char, BLOCK_SIZE>>();
char content_char = 'A' + (i % 26);
memset(write_buf->data(), content_char, BLOCK_SIZE);
off_t offset = i * BLOCK_SIZE;
auto result = std::make_shared<IOResult>();
write_results.push_back(result);
pool.enqueue([fd, offset, write_buf, result] {
ssize_t ret = pwrite(fd, write_buf->data(), BLOCK_SIZE, offset);
auto completed = true;
if (fsync(fd) == -1) {
std::cerr << "fsync failed" << std::endl;
completed = false;
}
{
std::lock_guard<std::mutex> lock(result->mutex);
result->fd = fd;
result->offset = offset;
result->result = ret;
result->completed = completed;
result->buffer = std::move(write_buf);
}
result->cv.notify_one();
});
}
// random read
std::vector<std::shared_ptr<IOResult>> read_results;
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<> dis(0, IO_COUNT - 1);
for (int i = 0; i < IO_COUNT; ++i) {
int block_num = dis(gen);
off_t offset = block_num * BLOCK_SIZE;
auto read_buf = std::make_shared<std::array<char, BLOCK_SIZE>>();
auto result = std::make_shared<IOResult>();
read_results.push_back(result);
pool.enqueue([fd, offset, read_buf, result] {
ssize_t writen = pread(fd, read_buf->data(), BLOCK_SIZE, offset);
{
std::lock_guard<std::mutex> lock(result->mutex);
result->result = writen;
result->fd = fd;
result->offset = offset;
result->completed = true;
result->buffer = std::move(read_buf);
}
result->cv.notify_one();
});
}
// wait for all write operations to complete
bool write_all_success = true;
for (auto &result : write_results) {
std::unique_lock<std::mutex> lock(result->mutex);
result->cv.wait(lock, [&result] { return result->completed; });
if (result->result != BLOCK_SIZE) {
write_all_success = false;
std::cerr << "IO operation failed with return: " << result->result << std::endl;
}
}
// wait for all read operations to complete
bool read_all_success = true;
for (auto &result : read_results) {
std::unique_lock<std::mutex> lock(result->mutex);
result->cv.wait(lock, [&result] { return result->completed; });
if (result->result != BLOCK_SIZE) {
read_all_success = false;
std::cerr << "IO operation failed with return: " << result->result << std::endl;
} else {
// check data integrity
char expected_char = 'A' + (result->offset / BLOCK_SIZE) % 26;
std::vector<char> compare_buffer(BLOCK_SIZE, expected_char);
if (std::memcmp(result->buffer->data(), compare_buffer.data(), BLOCK_SIZE) != 0) {
read_all_success = false;
std::cerr << "Data integrity check failed at offset: " << result->offset
<< std::endl;
}
}
}
auto end_time = std::chrono::high_resolution_clock::now();
if (write_all_success && read_all_success) {
std::cout << "All IO operations completed successfully!" << std::endl;
std::cout << "Total IO operations: " << IO_COUNT * 2 << std::endl;
std::chrono::duration<double> elapsed = end_time - start_time;
std::cout << "Elapsed time: " << elapsed.count() << " seconds" << std::endl;
std::cout << "IOPS: " << IO_COUNT * 2 / elapsed.count() << std::endl;
std::cout << "Throughput: "
<< static_cast<double>(IO_COUNT * 2 * BLOCK_SIZE) / elapsed.count() /
(1024 * 1024)
<< " MB/s" << std::endl;
} else {
std::cout << "Some IO operations failed!" << std::endl;
}
}2.3 初始化并运行
int main(int argc, char *argv[]) {
const std::string test_file = "io_pool_test.bin";
size_t num_io_threads = 4;
if (argc > 1) {
try {
num_io_threads = std::stoul(argv[1]);
if (num_io_threads == 0) {
std::cerr << "Thread count must be greater than 0, using "
"default value 4"
<< std::endl;
num_io_threads = 4;
}
} catch (const std::exception &e) {
std::cerr << "Invalid thread count argument, using default value 4: " << e.what()
<< std::endl;
}
}
std::cout << "Using IO thread pool size: " << num_io_threads << std::endl;
int fd = open(test_file.c_str(), O_RDWR | O_CREAT | O_TRUNC, 0644);
if (fd == -1) {
std::cerr << "Failed to open file" << std::endl;
return 1;
}
try {
IOThreadPool pool(num_io_threads);
simulate_user_rpc(pool, fd);
} catch (const std::exception &e) {
std::cerr << "Error: " << e.what() << std::endl;
close(fd);
return 1;
}
close(fd);
return 0;
}运行一下看看
➜ snip git:(master) ✗ g++ -Wall -Wextra -g -o 04 ./04_io_thread_pool.cpp
➜ snip git:(master) ✗ ./04 8
Using IO thread pool size: 8
All IO operations completed successfully!
Total IO operations: 1000000
Elapsed time: 89.6841 seconds
IOPS: 11150.3
Throughput: 43.5557 MB/s3 性能和讨论
笔者设置不同的线程数,在同机器上的 SATA SSD 和 NVMe SSD 上尝试。其中,IO 大小 4KiB,关注 IOPS。
SATA SSD
| 设备类型 | 线程数 | 总操作数 | 耗时(秒) | IOPS | 吞吐量(MB/s) |
|---|---|---|---|---|---|
| SATA SSD | 2 | 1,000,000 | 33.7835 | 29,600.2 | 115.626 |
| SATA SSD | 8 | 1,000,000 | 25.2971 | 39,530.3 | 154.415 |
| SATA SSD | 64 | 1,000,000 | 26.4295 | 37,836.5 | 147.799 |
| SATA SSD | 128 | 1,000,000 | 29.108 | 34,354.8 | 134.199 |
| SATA SSD | 256 | 1,000,000 | 34.9604 | 28,603.8 | 111.733 |
| SATA SSD | 512 | 1,000,000 | 43.883 | 22,787.8 | 89.015 |
NVMe SSD
| 设备类型 | 线程数 | 总操作数 | 耗时(秒) | IOPS | 吞吐量(MB/s) |
|---|---|---|---|---|---|
| NVMe SSD | 2 | 1,000,000 | 30.7639 | 32,505.7 | 126.975 |
| NVMe SSD | 8 | 1,000,000 | 15.191 | 65,828.4 | 257.142 |
| NVMe SSD | 64 | 1,000,000 | 12.6304 | 79,173.9 | 309.273 |
| NVMe SSD | 128 | 1,000,000 | 20.4492 | 48,901.6 | 191.022 |
| NVMe SSD | 256 | 1,000,000 | 43.5615 | 22,956.1 | 89.672 |
| NVMe SSD | 512 | 1,000,000 | 55.7664 | 17,931.9 | 70.047 |
可以看到,我们的线程数从 2 开始增加,性能逐渐提升。但线程数过大之后,反而逐渐下降。相比于单线程顺序读写,使用线程池模式无疑提高了我们系统的 IO 性能!真是令人愉悦。
但开发者要时刻记得我们最初的动机:同步 IO 不能榨干硬件性能,所以用线程池来凑。但随着线程数量增长,上下文切换带来的代价开始逐渐显现,系统的瓶颈反而逐渐转移到了线程切换和线程间同步上面。此时操作系统的 CPU 消耗也会变高
观察到 SATA SSD 在线程池模型下、线程数为 8 时性能较好,初步认为达到了硬件性能预期。我们也有理由怀疑,虽然 NVMe SSD 在线程数为 64 时表现较好,是不是远远没有达到其硬件能力? 更多地掣肘我们的,可能是线程间的切换和同步代价了(考虑线程锁效率?NUMA消耗?大量线程切换导致的 sys cpu 占用等等)。单个 IO 线程只能同时进行一个 IO,而我们又不能无限地增大线程数量。
笔者深深地认为,选择合适 IO 模型,一定要评估我们系统的实际需求和硬件的规模。比如:
- 系统需求:注重高扩展性?高性能?
- 硬件规模:HDD/SSD?单机器 CPU 和 disk 配比?