FAST'26 | LESS: 纠删码存储中 I/O 高效修复
LESS is More for I/O-Efficient Repairs inErasure-Coded Storage
本文为 FAST'26 顶会论文,原文链接为 LESS is More for I/O-Efficient Repairs inErasure-Coded Storage
@article{chengless,
title={LESS is More for I/O-Efficient Repairs in Erasure-Coded Storage},
author={Cheng, Keyun and Li, Guodong and Li, Xiaolu and Hu, Sihuang and Lee, Patrick PC}
}团子观点
Reed-Solomon (RS) 确实是当前分布式存储中离不开的编码方式。本文基于广泛使用的 RS 编码,通过对条带、子条带的扩展和划分,并通过数学证明了其在范德蒙矩阵 RS 编码下的正确性。
为什么分布式存储仍然钟爱 EC 编码和 RS 编码
译者经常和同事讨论这个话题。近年来有许多结构复杂的编码,它们往往通过更复杂的拓扑组合和逻辑达到了更好的性能、成本或修复效率。
造型优美
但开发者和工程应用往往喜欢大道至简的东西。在分布式的混沌系统中,编码的造型越优美、越对称,越能够降低开发者和运维者的心智负担。
EC 编码就是一个这样的编码。虽然修复时候有较大的 IO 放大,但就是这样一个 EC(n, k) 的结构,非常易于理解和落地。
站在巨人的肩膀上
现代的硬件和基础库往往对 RS 进行了高度的优化。直接使用工业级编码库省去了很多工作量。
LRC 又如何
译者的同事有一个观点:LRC 是罕见的能够以小博大的优美方法。通过简单加入 XOR 本地块,略微增大冗余却大大降低了修复代价。
LRC 同时保持了心智友好。虽然不是 MDS 的,但是仍然可以轻松在一张纸上画出分片结构。
LESS
本文回归到 RS 码的线性叠加逻辑上。通过“分层扩展子条带”的设计,它仅需极小的子分块数(如 )就能显著降低修复 I/O。
LESS 很好地继承了 RS 码的对称性,确保了数据块和校验块在修复时具有相同的成本。这种确定性对于运维调度来说,可能比不稳定的“理论最优”更可取。
LESS 可以作为 RS 码的一个“插件化”增强。如果读者正在寻找更低修复代价,同时又要求足够简约的编码方式,可以尝试此方法。
其他材料推荐
推荐以下材料
CubeFS技术揭秘 | 多AZ纠删码容灾技术: 非常好的工程文章,详细描述了 cubefs ec/lrc 的实现动机和细节,非常适合正在使用工业库构建自己编码系统的开发者参考。
Erasure-Code 系列文章 - OpenACID Blog: 从数学原理娓娓道来,并阐述了工业库的实现经验。
以下是 FAST 26 LESS 论文的全文翻译。
Abstract
I/O 效率对现代分布式存储中纠删码修复性能至关重要. 我们提出 LESS, 一系列面向修复优化的纠删码构造, 在单块修复中既减少访问的数据量又降低 I/O 寻道次数, 并保证各块之间的修复代价均衡. LESS 在广泛部署的 Reed-Solomon 编码之上叠加多个扩展子条带, 并可通过配置在数据访问量与 I/O 寻道之间权衡. 评估表明, 在 HDFS 上 LESS 相较当前 I/O 最优纠删码, 单块修复与整节点恢复时间均有所缩短.
1 引言
纠删码(erasure coding)在现代分布式存储系统中被广泛采用(如 1234), 以在显著低于传统复制 5 的存储开销下提供容错. 然而纠删码带来高昂的修复代价: 重建单个失效块需要访问和传输远多于一块大小的数据, 导致带宽与 I/O 成本被放大. 近期综述 67 指出, 编码理论与系统社区均有大量工作致力于提升纠删码存储的修复效率, 主要集中在访问性能(如优化降级读 89)与存储可靠性(如降低平均数据丢失时间 103). 其中, 大量研究提出了面向修复优化的纠删码构造以缓解带宽与 I/O 成本(相关工作见 §2.2).
在现代分布式存储系统中, 随着网络技术(如 InfiniBand、RDMA、CXL)的快速发展与高速互联的普及, I/O 效率相比带宽效率已成为愈发关键的设计因素. 但 I/O 性能难以跟上网络提升, 尤其在随机访问负载下. 这促使我们构造以 I/O 效率为“一等公民”的利于修复的纠删码, 以实现高修复性能.
现有的利于修复的纠删码在修复时往往存在次优的 I/O 表现(§2.2). 例如, Clay 码 11 是当前最优的最小存储再生(MSR)码, 在单块修复中从理论上最小化从本地存储访问的数据量, 并最小化容错所需的存储冗余. 其核心思想是子分组(sub-packetization), 即将纠删码条带(即一起编码的一组块)划分为由同一块内偏移处子块构成的更小子条带. 在单块修复时, Clay 码从各子条带中读取最少数量的子块进行重建. 尽管最小化了数据访问, Clay 码为达到最优性需要指数级子分组, 并在修复时发起大量非连续 I/O 寻道以读取子块, 因 I/O 请求被放大而在 I/O 受限环境中显著损害修复性能. 本地可修复码(如 Azure LRC 3)可实现 I/O 高效的修复, 但存储冗余更高. 其他纠删码在最小存储冗余下支持小子分组 12131415, 但构造方式存在各种限制, 导致修复效率不足.
我们提出 LESS, 一族面向 I/O 高效修复的纠删码构造, 旨在(i)在小子分组(每条带可低至两个子条带)下同时减少访问的数据量与 I/O 寻道次数, (ii)在条带内所有块之间保持修复代价均衡(即各块的数据访问与 I/O 寻道代价相近). LESS 基于“扩展子条带分层”的思想, 通过在常规条带之上策略性地叠加多个扩展子条带(每条带长度更长), 使得单块修复(以及部分多块修复情形)可在单个扩展子条带内完成. LESS 在设计上注重实用性: 建立在广泛使用的 Reed-Solomon(RS)码 16(§2.1)之上以便于理解, 并保留 RS 码的实用性质; 同时支持可配置的子分组以在数据访问与 I/O 寻道之间权衡.
我们在本地集群的 HDFS 17 上实现并评估了 LESS. 相较 Clay 码, LESS 将单块修复时间与整节点恢复时间分别降低最多 与 . LESS 源码见: https://github.com/adslabcuhk/less.
2 背景
2.1 纠删码基础
我们考虑将数据组织为大块、固定块大小(如 HDFS 17 中 128 MiB、Facebook f4 4 中 256 MiB)的分布式存储系统, 以降低 I/O 开销. 此类系统通常受 I/O 限制, 网络带宽与磁盘 I/O(量级为 MiB/s)是主要性能瓶颈, 而非编解码的计算开销, 正如先前工作 8101819 所述. 纠删码通过对块故障提供容错来保证数据持久性, 这在归档存储等应用中至关重要. 我们关注 RS 码 16, 其在生产环境中广泛部署 12420. RS 码由参数 与 ()配置. RS 码将 个未编码数据块编码为 个校验块, 形成 块的条带, 并保证任意 块可重建全部 个数据块(即任意 块故障可容忍). 在分布式存储中, 多条带独立编码, 每条带分布在 个节点上以容忍任意 个节点故障.
RS 码满足三条实用性质: (i)最大距离可分(MDS), 即冗余( 倍数据大小)在容忍任意 块故障时最小; (ii)通用性, 即任意 、()在域足够大时均可构造 RS 码; (iii)系统码, 即每条带保留 个数据块供直接访问.
RS 编解码在伽罗瓦域 上使用 比特字的线性组合, 其中 21. 每个块可表示为任意 块在伽罗瓦域运算下的线性组合(详见 §3.1).
RS 码带来高修复带宽, 即修复过程中在节点间传输的数据量. 修复单个失效块需从其他节点读取同一条带的 块; 我们称该过程为常规修复, 适用于所有 MDS 码. 同时也会产生高修复 I/O, 即修复时从本地存储访问的数据量. 在高速网络中, 修复 I/O 成为主导瓶颈(§1).
2.2 修复优化相关工作
先前综述 [1, 33] 回顾了纠删码存储中优化单块修复性能的大量研究. 我们简述若干代表性利于修复的纠删码及其局限.
最小存储再生(MSR)码. MSR 码 22 在单块修复时最小化修复带宽, 同时保持 MDS 性质(即最小冗余). 其基于子分组, 将每块划分为 个子块, 并在各块同一偏移处形成 条由 个子块构成的子条带. 每个子块是条带内在 上其他 个子块的线性组合. 单块修复仅传输一部分子块, 达到最小修复带宽.
传统 MSR 码 22 要求节点读取并编码全部本地子块, 导致高修复 I/O. I/O 最优 MSR 码通过允许被访问数据直接发送而不经编码来最小化修复 I/O. 例如, 函数 MSR(F-MSR)码 823 要求 23 或 8, 且 为线性, 但非系统码. PM-RBT 码 24 为系统码但要求 , Butterfly 码 25 也为系统码但要求 且 为指数.
Clay 码 11 是当前 I/O 最优 MSR 码的代表: 系统码、支持一般 、并在 Ceph 26 中部署. 但 Clay 码强加指数级 (注: I/O 最优 MSR 码需要指数子分组 27). 尽管 Clay 码最小化修复 I/O, 却访问大量非连续子块并产生可观 I/O 寻道(即修复时对本地存储的非连续读取次数), 因处理大量 I/O 请求的开销而导致修复性能次优 15.
本地可修复码(LRC). LRC 3282930 降低单块修复的修复 I/O. 例如 Azure-LRC 3 将数据块划分为本地组, 每组增加一个本地校验块. 修复失效的数据块或本地校验块仅访问其所在本地组的块. 但 Azure-LRC 将条带内全部数据块编码进全局校验块, 后者修复仍依赖常规修复. 部分 LRC 变体支持对全局校验块的本地修复 29, 但 LRC 非 MDS 且冗余高于 RS 码.
小子分组 MDS 码. 为限制 I/O 寻道, 部分 MDS 码允许小 并降低修复 I/O. Hitchhiker 码 14 通过 piggyback 函数跨子条带组合子块, 使用 条 RS 子条带, 相较 RS 码将数据块修复 I/O 降低 25–45%; 但校验块修复仍为常规修复. HashTag 码 13 在一般 与 下降低数据块修复 I/O; 其扩展码 12 同时降低数据块与校验块的修复 I/O, 但要求 且 为 的倍数. 弹性变换(ET)15 将 RS 码转换为具有可配置 的利于修复的纠删码, 但变换限制了构造灵活性并制约进一步修复改进.
修复高效算法. 本研究聚焦纠删码构造; 另有工作设计修复高效算法, 如基于 XOR 纠删码的最小 I/O 恢复搜索 [13, 39] 或修复并行化 [17, 18, 20, 32]. 受底层纠删码约束, 它们无法最小化修复 I/O.
2.3 目标
表 1 总结了利于修复的纠删码及其局限, 包括: 非 MDS(如 Azure-LRC 3)、参数受限(如 F-MSR 823、PM-RBT 24、Butterfly 25)、非系统形式(如 F-MSR)、指数子分组(如 Butterfly、Clay 11)以及仅对数据块有改进(如 Hitchhiker 14、HashTag 13).
这些局限催生了 LESS: 一族以 I/O 效率为目标的利于修复的纠删码. 我们观察到修复性能同时取决于修复 I/O 与 I/O 寻道. 最小化修复 I/O 会引入指数 2711(进而带来高 I/O 寻道), 并可能抵消修复性能收益. LESS 目标是在小且可配置的 下接近最小修复 I/O, 以限制 I/O 寻道. 设计目标包括:
• 保持 RS 码性质: LESS 为 MDS、支持一般 、并保持系统码形式, 与 RS 码一致. • I/O 高效修复: LESS 在三方面实现 I/O 高效修复: (i)降低修复 I/O, (ii)降低 I/O 寻道(如 , 3 或 4), (iii)修复代价均衡(即数据块与校验块在修复 I/O 与 I/O 寻道上的代价相近). LESS 还允许 可配置. • 单块与多块修复效率: 早期工作主要优化单块修复(实践中占主导, 如 (14,10) 编码条带中约 98% 的故障 31). 但宽条带码(即 、 较大)的出现使多块修复更常见 28. LESS 同时针对两种场景.
| Codes | MDS | Parameters | Systematic | Sub-packetization | Reduced repair I/O for data/parity |
| F-MSR [^6][^8] | Yes | n-k≤3 | No | α=n-k | Yes |
| PM-RBT [^27] | Yes | n≥2k-1 | Yes | k-1≤α≤n-k | Yes |
| Butterfly [^22] | Yes | n-k=2 | Yes | α=2k-1 | Yes |
| Clay [^36] | Yes | general (n,k) | Yes | α=(n-k){n/n-k} | Yes |
| Azure-LRCs [^10] | No | general (n,k) | Yes | α=1 | No |
| Hitchhiker [^29] | Yes | general (n,k) | Yes | α=2 | No |
| HashTag [^16] | Yes | general (n,k) | Yes | 2≤α≤(n-k){n-k} | No |
| HashTag+ [^15] | Yes | general (n,k) | Yes | 4≤α≤(n-k){n-k} | Yes |
| ET [^35] | Yes | general (n,k) | Yes | 2≤α≤(n-k){n-k} | Yes |
| LESS | Yes | general (n,k) | Yes | 2≤α≤n-k | Yes |
Table 1: 修复高效纠删码对比.
3 LESS 设计
LESS 由可配置参数 构造, 其中 且 . 其核心思想是分层多个扩展子条带, 每条带由子块构成并用基于 Vandermonde 的 RS 码编码, 使得单块修复始终从同一扩展子条带读取子块. 若失效块共享同一扩展子条带, LESS 还可实现 I/O 高效的多块修复.
3.1 基于 Vandermonde 的 RS 码
LESS 建立在基于 Vandermonde 的 RS 码之上. 基于 Vandermonde 的 RS 码用校验矩阵 32 定义 个数据块 与 个校验块 在 上的关系, 即校验方程:
其中 为长度 的列向量, 为与块 关联的 中互异编码系数, . 在 中加法等价于按位 XOR. 校验矩阵 保证任意 列中 列线性无关, 从而可从剩余 块重建任意 块.
编码根据式 (1) 由 个数据块计算 个校验块:
对任意 块的解码为: 将(i)其对应列向量子矩阵的逆, (ii)剩余 块对应列向量子矩阵, (iii)该 块, 按式 (1) 相乘.
3.2 示例说明
我们通过一个例子说明 LESS. 图 1 给出 的 LESS 条带, 其中每块 ()有两个子块 与 . LESS 将 12 个子块组织成三个 RS 编码的扩展子条带 , 与 . 每个扩展子条带可容忍任意两个子块故障, 整条带因 MDS 性质可容忍任意两块故障.
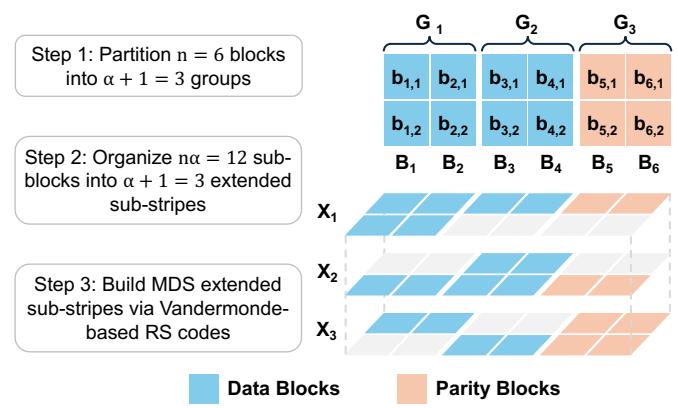
Figure 1: LESS 条带的编码设计.
构造. 首先将 12 个子块划分, 使每个子块恰好属于两个扩展子条带. 这种重叠结构保证每个扩展子条带可由另外两个扩展子条带导出. 例如 包含四个数据子块与四个校验子块, 它们分别仅属于 或 之一, 故 可由 与 导出.
接着基于 Vandermonde RS 码为扩展子条带选取编码系数. 从 中为 选取 12 个互异系数 (, ).
最后通过编码前两个扩展子条带 与 计算校验块 与 . 用 的六个数据块计算 与 , 用 的另外六个数据块经 (8,6) 基于 Vandermonde 的 RS 编码(基于式 (1))计算 与 :
其中 . 编码系数经精心选择, 使 在无需显式编码的情况下自然形成 (8,6) 基于 Vandermonde 的 RS 条带. 原因是 也满足校验方程(式 (1)), 且恰好为 与 校验方程之和:
单块修复. 设 失效. LESS 从 修复 与 , 需读取六个子块 , , , , , , 相较 RS 码的常规修复(四整块)减少 25% I/O. 注意 LESS 的修复 I/O 削减适用于所有数据块与校验块. 对任意块, 其子块必属于某一扩展子条带, 故单块修复始终读取六个子块.
3.3 构造
下面详述如何为可配置参数 (, )构造 LESS 条带. LESS 条带包含 个块 (), 每块有 个子块 ()(即 条子条带). LESS 将子块组织为 个扩展子条带, 每个可容忍任意 个子块故障. 构造步骤如下.
Step 1(块分组). 将 块划分为 个块组 (), 各组块数最多相差 1. 的块数 为:
图 1 中将六块分为三组: , , .
Step 2(扩展子条带分层). 将 个子块组织为 个扩展子条带 (). 记 为包含块 的块组下标(即若 , 则 ). 前 个 ()各自包含 中全部子块加上第 条子条带的全部子块; 包含 中全部子块以及满足 的所有子块 . 的子块数 为:
其中 对应一条子条带中的子块数, 对应 中不属于同一条子条带的其余子块. 每个子块恰好属于两个扩展子条带. 特别地, 包含前 个扩展子条带中的子块, 且每个子块仅出现在前 个扩展子条带之一. 图 1 中将子块组织为三个扩展子条带(, , ), 各含八个子块.
Step 3(构建 MDS 扩展子条带). 目标是使每个扩展子条带 ()成为可容忍任意 个子块故障的 基于 Vandermonde 的 RS 条带. 编码过程如下. 首先从 选取 个互异编码系数 (, ), 使 满足校验方程:
其中 为长度 的 Vandermonde 列向量. 任意 个 Vandermonde 列向量线性无关保证 为 RS 编码条带. 接着按顺序(从 到 )编码前 个扩展子条带 以计算校验块 (). 具体地, 对每个 (), 用 RS 编码(基于式 (2) 与 (5))计算 个校验子块 (). 无需显式编码, 在前 个扩展子条带编码后自动形成基于 Vandermonde 的 RS 条带. 图 1 中基于 Vandermonde RS 编码用 与 计算 与 , 之后 也形成 (8,6) 基于 Vandermonde 的 RS 条带.
MDS 性质. 为使 LESS 条带容忍任意 块故障, 须从伽罗瓦域中谨慎选取 个互异编码系数 . 定理 1 表明在域足够大时总可找到这样的系数. 证明见附录.
定理 1. 对 LESS, 当 时, 总可在 中找到 个互异编码系数 (, )使 LESS 为 MDS.
定理 1 给出伽罗瓦域大小的充分条件. 实践中对典型编码参数, 所需系数可在更小域( 或 )中找到. 我们实现中可用本原元 通过乘法方式生成 个编码系数:
其中 ()为 在其块组 中的位置(即 为 中第 块). 例如图 1 中 为 中第二块, 故 , . (6,4,2) LESS 的本原元为 , 与 在 中分别为 与 . 可通过暴力搜索(即枚举校验矩阵任意可能子矩阵并检验线性无关)找到可行本原元. 注意可行本原元的搜索仅在构造时进行一次. 附录中给出校验矩阵的构成方式及常用 (, )的可行本原元.
3.4 修复
LESS 支持在扩展子条带内高效修复单块故障, 以及当失效块位于同一扩展子条带时的部分多块故障修复.
单块修复. 对 ()中失效块 (), 使用 内的子块修复 , 包含 的全部子块. 因 为 RS 编码条带, 可容忍任意 个子块故障. 个失效子块可用 的校验方程(式 (5))重建. 为减少访问块数, 优先传输 的 个可用子块, 再传输其余块组的 个可用子块.
多块修复. LESS 对多块修复也有益, 即同时修复同一条带上多块. 当 时, 若所有失效块位于同一块组(设为 , ), LESS 可在一个扩展子条带内修复任意 块故障. 因所有失效子块均在 中, 且 , 失效子块可在 内修复. 其他多块故障情形 LESS 退化为常规修复(读取 块). 例如在 (14,10,2) LESS 条带(图 2)中, 修复 中两块 与 (即子块 , , , 均在 中)可利用 的 (19,15) RS 编码, 仅需 15 个子块, 相较 (14,10) RS 码常规修复减少 25% 修复 I/O.
3.5 LESS 中的 I/O 高效修复
LESS 在三个方面实现 I/O 高效修复: (i)修复 I/O, (ii)I/O 寻道, (iii)各块间修复代价均衡.
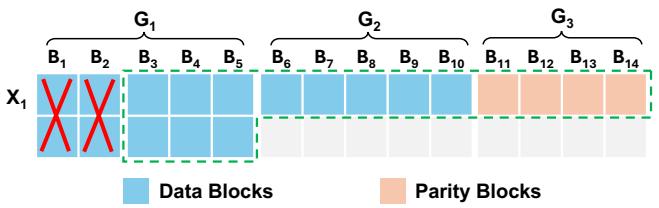
Figure 2: LESS 中的双块修复.
修复 I/O. 对 中块 ()(回忆 ), 我们读取 个子块, 因使用 RS 码修复. 由式 (3) 与 (4), 的修复 I/O(以子块计)为:
当 (实践中常见)时, 该值严格小于 RS 码常规修复的 I/O, 因为 .
I/O 寻道. 对单块故障, LESS 将 I/O 寻道限制为 . 修复 中 需从 读取 个子块, 包括: (i)来自 的 个连续子块, 可用 次寻道读取; (ii)来自其余块的 个子块, 各需一次寻道. 由式 (3)(4), I/O 寻道总数为 .
各块间修复代价均衡. 由式 (7), 修复条带内任意数据块或校验块的修复 I/O 相近, 最多相差 个子块. 且修复在 个可用块上各产生恰好一次 I/O 寻道. 因此 LESS 实现了各块间修复代价的均衡.
4 评估
我们通过数值分析与测试台实验评估 LESS, 并回答两个问题: (i)LESS 的实际修复性能是否与其理论改进一致? (ii)系统配置如何影响修复性能?
4.1 数值分析
Exp#A1(单块修复). 在单块修复下将 LESS 与系统 MDS 码(RS、Clay、Hitchhiker、HashTag、ET)比较. 对 HashTag、ET 与 LESS 将 从 2 取到 . 我们度量修复 块中每一块时的平均、最小与最大修复 I/O(以块计)以及 I/O 寻道总数. 重点考察 , 即 Facebook f4 4 的默认配置. 表 2 表明在 时, LESS 在有限 I/O 寻道下具有比其他码(除最小化修复 I/O 的 Clay 外)更低的修复 I/O. 当 时, LESS 相较 RS、Hitchhiker、HashTag()与 ET()将平均修复 I/O 分别降低 53.6%、38.1%、23.1% 与 20.7%, 并将 Clay 的平均 I/O 寻道数降低 95.5%.
| Codes | α | Repair I/O | # I/O seeks | ||
| Avg | Min/Max | Avg | Min/Max | ||
| RS | 1 | 10.00 | 10.00 / 10.00 | 10.000 | 10 / 10 |
| Clay | 256 | 3.25 | 3.25 / 3.25 | 286.00 | 13 / 832 |
| Hitchhiker | 2 | 7.50 | 6.50 / 10.00 | 10.86 | 10 / 13 |
| HashTag | 2 | 7.07 | 5.50 / 10.00 | 10.71 | 10 / 11 |
| 3 | 6.67 | 4.34 / 10.00 | 12.64 | 10 / 20 | |
| 4 | 6.04 | 4.00 / 10.00 | 12.14 | 10 / 13 | |
| ET | 2 | 7.50 | 7.50 / 7.50 | 11.00 | 11 / 11 |
| 3 | 7.14 | 6.67 / 7.67 | 13.43 | 12 / 14 | |
| 4 | 5.86 | 5.50 / 6.25 | 14.29 | 13 / 15 | |
| LESS | 2 | 7.36 | 7.00 / 7.50 | 11.00 | 11 / 11 |
| 3 | 5.71 | 5.33 / 6.00 | 12.00 | 12 / 12 | |
| 4 | 4.64 | 4.00 / 4.75 | 13.00 | 13 / 13 | |
Table 2: (14, 10) 单块修复分析.
| Codes / (n,k) | Avg. Repair I/O / Avg. # of I/O seeks | ||
| (80,76) | (100,96) | (124,120) | |
| RS | 76 / 76 | 96 / 96 | 120 / 120 |
| LESS (α = 4) | 31 / 79 | 39 / 99 | 48.6 / 123 |
Table 3: 宽条带码单块修复分析.
(a) 修复 I/O
(b) I/O 寻道次数
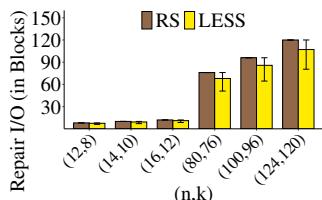
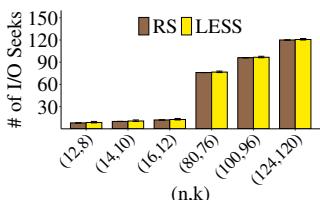
Figure 3: 不同 下双块修复分析.
LESS 也改善宽条带修复. 表 3 给出结果(部分参数见 [9, 12]). 例如对 (124,120), LESS()在有限额外 I/O 寻道下将 RS 的修复 I/O 降低 59.5%.
Exp#A2(多块修复). 我们研究不同 下 LESS 与 RS 码(常规修复)的双块修复 I/O 与 I/O 寻道. 对所有 种块故障组合取平均, 并给出最小/最大误差条. 图 3 为结果. LESS 在 27.3–32.8% 的双块故障情形下降低修复 I/O, 且 I/O 寻道开销有限. 例如对 (14,10), LESS()将 RS 的平均修复 I/O 降低 7.4%, 并在 28.6% 的情形下改善修复. 对宽条带如 (124, 120), LESS()将 RS 的平均修复 I/O 降低 10.8%, 并在 32.8% 的情形下改善修复.
4.2 测试台实验
实现. 我们在 Hadoop 3.3.4 HDFS 33 之上的 OpenEC(纠删码中间件)19 上实现 LESS, 并使用 Jerasure 34 进行编码运算. 对比中还包括 RS、Clay、Hitchhiker、HashTag 与 ET. 原型在 OpenEC 上新增约 8.7K 行 C++ 代码.
HDFS 使用一个 NameNode 做存储管理与多个 DataNode 做存储. HDFS 将数据组织为固定大小块, 每块再划分为多个 packet. 同一块偏移处的 packet 一起编码, 支持跨 packet 的流水线编码. 我们的原型遵循该 packet 级流水线实现.
方法. 在通过 10 Gbps 以太网交换机连接的 15 台机器本地集群中进行测试台实验. 每台机器配置四核 3.4 GHz Intel i5-7500 CPU、16 GiB 内存、7200 RPM 1 TB SATA HDD 与 Ubuntu 22.04. 使用 Wondershaper 35 配置每台机器的网络带宽. 默认使用一台机器运行 NameNode、14 台运行 DataNode. 按先前工作 193015, 默认设置 、64 MiB 块、256 KiB packet、1 Gbps 网络带宽.
我们评估: (i)单块修复时间(即从发起对失效块的修复请求到该块修复完成的平均时间, 对 块取平均), (ii)整节点恢复时间(即修复单个失效 DataNode 上全部块的总时间). 整节点恢复中修复来自不同条带的 20 块(每条带一块)18, 节点 ID 在集群中跨条带随机分配, 故失效节点丢失的块对应各条带中不同块位置. 结果对 10 次运行取平均, 并给出基于 Student t 分布的 95% 置信区间.
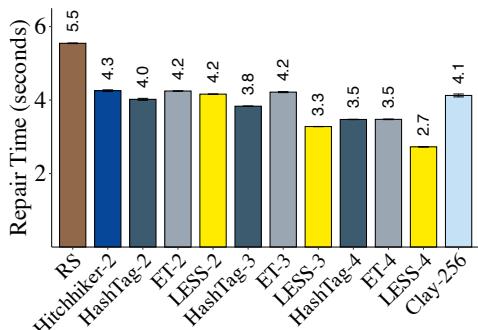
Exp#B1(单块修复). 图 4(a) 表明 LESS 因修复 I/O 与 I/O 寻道的减少而有效缩短单块修复时间. 例如 LESS()相较 RS、Hitchhiker、HashTag()、ET()与 Clay 将单块修复时间分别降低 50.8%、35.9%、21.5%、21.5% 与 33.9%.
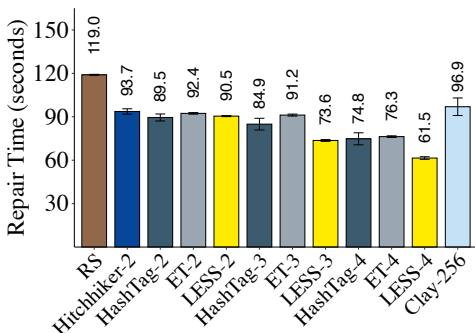
Exp#B2(整节点恢复). 图 4(b) 表明 LESS 也缩短整节点恢复时间. 例如 LESS()相较 RS、Hitchhiker、HashTag()、ET()与 Clay 的降幅分别为 48.3%、34.3%、17.8%、19.4% 与 36.6%.
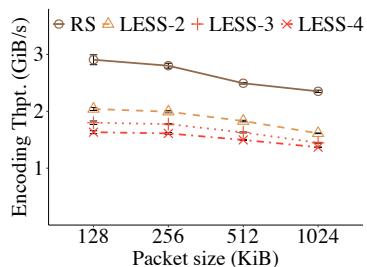
Exp#B3(编码吞吐). 在单机上测量编码吞吐(即每秒编码的数据量). 在内存中构造 (14,10) 条带并填入随机字节进行编码. 图 4(c) 给出 packet 大小从 128 KiB 到 1024 KiB 的结果. 对 256 KiB packet, RS 达 2.8 GiB/s, LESS()达 1.6 GiB/s. 对宽条带如 (124, 120) 与 256 KiB packet, RS 与 LESS()分别达 2.6 GiB/s 与 1.1 GiB/s(图中未示). 两种码的编码吞吐随 packet 增大而下降, 因更多数据需装入 CPU 缓存以编码. LESS 因子分组而编码吞吐低于 RS, 但其编码吞吐仍超过 1 GiB/s, 且与带宽与 I/O 瓶颈(§2)相比计算开销有限. 评估为单线程; 编码吞吐可通过跨条带多线程进一步提升.
(a) 单块修复时间
(b) 整节点恢复时间
(c) 编码吞吐
Figure 4: (14, 10) 修复性能. 图 (a)(b) 中在各码旁标注 (如 LESS-4 表示 ).
(a) 网络带宽影响
(b) packet 大小影响
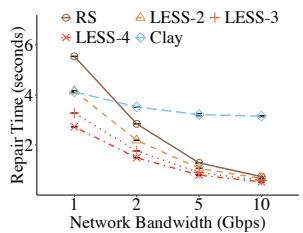
Figure 5: 配置对 (14,10) 单块修复的影响.
Exp#B4(网络带宽影响). 通过 Wondershaper 将网络带宽从 1 Gbps 调至 10 Gbps, 研究对单块修复时间的影响. 图 5(a) 表明随带宽增加, Clay 受显著 I/O 寻道开销影响, 而 LESS 因小子分组有效缩短单块修复时间. 例如在 10 Gbps 带宽下, LESS()将 RS 与 Clay 的单块修复时间分别降低 28.6% 与 83.3%. 总体而言, LESS 在不同网络带宽下均保持较低的单块修复时间.
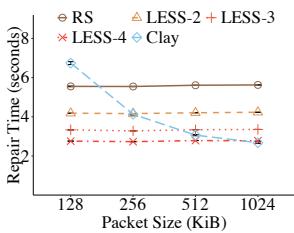
Exp#B5(packet 大小影响). 将 packet 大小从 128 KiB 调至 1024 KiB. 图 5(b) 表明在较小 packet 下, Clay 因处理大量子块而产生显著 I/O 开销, 而 LESS 保持稳定修复性能. 例如对 128 KiB packet, LESS()将 RS 与 Clay 的单块修复时间分别降低 59.1% 与 50.4%.
5 结论
LESS 是一族通过扩展子条带分层设计、面向 I/O 高效修复的纠删码, 在减少修复 I/O 与 I/O 寻道的同时保证各块间修复代价均衡. 其具有多条实用性质: MDS、通用参数、系统码及可配置子分组. 数值分析与测试台实验表明 LESS 相较当前利于修复的纠删码具有修复收益.
References
附录 A: MDS 性质的证明
我们证明定理 1: 在域足够大时 LESS 为 MDS. 证明基于 LESS 的校验矩阵.
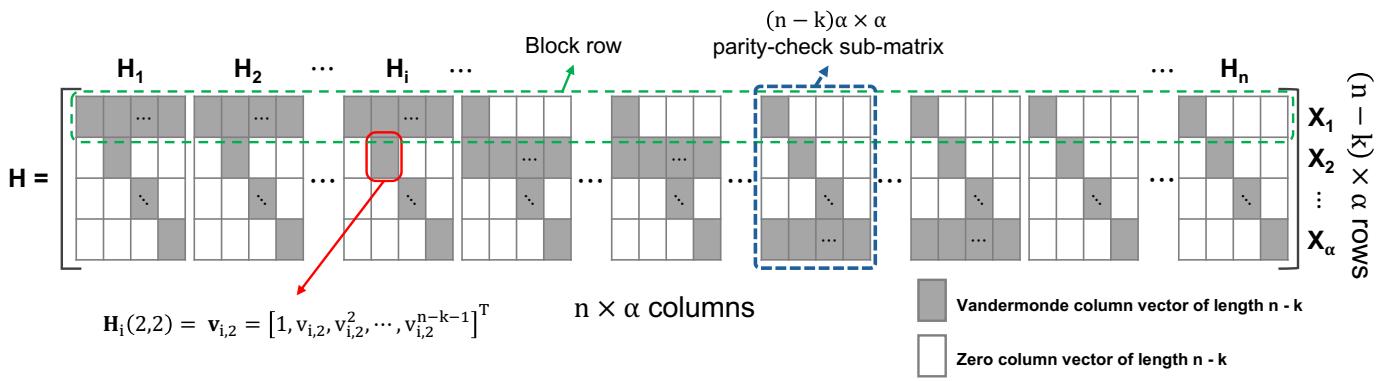
Figure 6: LESS 条带的校验矩阵.
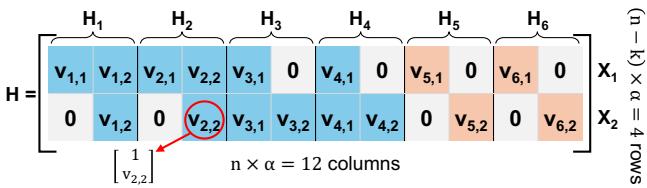
Figure 7: (6, 4, 2) LESS 条带的校验矩阵.
LESS 的校验矩阵. LESS 条带的校验矩阵 为 矩阵. 我们将 视为 块矩阵, 每元素为长度 的列向量. 将 划分为 个校验子矩阵 , 其中每个 ()为 块矩阵. 定义块行为 的一行中的 个元素. 在第 个块行、第 列(, )的元素为
图 6 给出 LESS 的校验矩阵. 将块 写为子块的列向量. 由校验矩阵, 前 个扩展子条带的 个校验方程可写为
由式 (5) 与 (9), 第 个块行可写为扩展子条带 的校验方程:
图 7 给出 (6,4,2) LESS 的校验矩阵. 校验矩阵 由两个块行与六个校验子矩阵组成. 第一、二块行分别可由 与 的校验方程导出.
定理 1 的证明. 为证 LESS 为 MDS, 可验证 LESS 的校验矩阵满足: 从 个校验子矩阵中任选 个可构成 可逆方阵. 任一可逆方阵行列式非零. 要保证校验矩阵所有可能方阵均可逆, 可将这些方阵的行列式相乘并保证乘积非零.
从 个校验子矩阵中选 个构成方阵共有 种. 每个方阵的行列式可视为编码系数 (, )的多项式. 每个 仅出现在一个校验子矩阵(即 )中, 且包含 的方阵有 种. 故 在此类方阵行列式中的次数为 . 将所有方阵行列式相乘后, 每个 的次数为 . 当 时, 可在 中选取 个互异编码系数使行列式乘积非零, 这可由 Noga Alon 的组合零点定理证明.
表 4 给出基于暴力搜索、在 与 中常用编码参数(, )的可行本原元.
| n-k | α | n | Galois Fields | p |
| 2 | 2 | n ≤ 127 | GF(28) | 2 |
| 3 | 2 | n ≤ 44 | GF(28) | 50 |
| n ≤ 127 | GF(216) | 2 | ||
| 3 | n ≤ 40 | GF(28) | 14 | |
| n ≤ 127 | GF(216) | 2 | ||
| 4 | 2 | n ≤ 23 | GF(28) | 6 |
| n ≤ 127 | GF(216) | 46 | ||
| 3 | n ≤ 17 | GF(28) | 2 | |
| n ≤ 127 | GF(216) | 1362 | ||
| 4 | n ≤ 16 | GF(28) | 14 | |
| n ≤ 127 | GF(216) | 635 |
Table 4: 常用编码参数的可行本原元.
附录 B: Artifact 附录
Abstract
LESS 是一族通过扩展子条带分层、旨在提升修复 I/O 效率的纠删码, 目标为减少修复 I/O 与 I/O 寻道并在各块间保持修复代价均衡. 我们在 Hadoop 3.3.4 HDFS 之上的 OpenEC(纠删码中间件)上实现 LESS.
Scope
本 artifact 为研究驱动型原型, 可用于验证论文中 LESS 的概念、设计与评估结果.
Contents
artifact 包含: • src/, LESS 作为 OpenEC 代码库补丁的实现. • scripts/, 用于复现评估结果的评估脚本与配置文件. • README.md, 实现概览及运行原型所需信息. • AE_INSTRUCTION.md, artifact 评估的详细说明.
Hosting
artifact 托管于 GitHub: https://github.com/adslabcuhk/less. 评估使用版本 v1.0.0.
Requirements
硬件依赖. 建议使用 15 台机器运行原型与评估脚本. 机器需通过 10 Gbps 网络互联并可互相访问. 每台机器建议配置四核 CPU、16 GiB 内存、7200 RPM SATA HDD 及以上. 默认纠删码参数 下至少需 15 台机器组成存储集群. 我们使用一台运行 HDFS NameNode, 其余运行 HDFS DataNode.
软件依赖. artifact 在 Ubuntu 22.04 LTS 上开发与测试, 依赖: • OpenEC: g++, cmake, redis, hiredis, ISA-L, gf-complete • Hadoop HDFS: openjdk-8-jdk, maven • scripts: expect, python3, wondershaper
Testbed Setup
请按以下步骤搭建测试台: • 按上述准备硬件依赖. • 从 https://github.com/adslabcuhk/less/releases 下载 artifact(版本 v1.0.0). • 使用 tar -zxvf less.tar.gz 解压; 执行 cd less 进入项目目录. • 按 AE_INSTRUCTION.md 搭建测试台并用提供的评估脚本运行实验. 测试台搭建约需 5 小时, 视硬件配置而定.
Evaluation
Artifact 声明. 我们的目标是展示 LESS 在提升修复性能上的有效性. 对数值分析(Exp#A1、Exp#A2), 预期结果与论文一致. 对测试台实验(Exp#B1–Exp#B5), 预期 LESS 相较基线纠删码缩短单块修复与整节点恢复时间. 但测试台结果可能因集群规模、机器规格、操作系统与软件版本等因素与论文存在差异.
实验.
Exp#A1(单块修复). 预期: 得到与表 2、表 3 一致的结果, 表明 LESS 降低 RS、Hitchhiker、HashTag、ET 的平均修复 I/O, 并降低 Clay 的平均 I/O 寻道数. 约 2 分钟.
Exp#A2(多块修复). 预期: 得到与图 3 一致的结果, 表明 LESS 降低 RS 的平均修复 I/O, 且 I/O 寻道数与 RS 相近. 约 1 分钟.
Exp#B1(单块修复). 预期: 得到与图 4(a) 一致的结果, 表明 LESS 缩短 RS、Hitchhiker、HashTag、ET、Clay 的单块修复时间. 约 2 小时.
Exp#B2(整节点恢复). 预期: 得到与图 4(b) 一致的结果, 表明 LESS 缩短 RS、Hitchhiker、HashTag、ET、Clay 的整节点恢复时间. 约 2 小时.
Exp#B3(编码吞吐). 预期: 得到与图 4(c) 一致的结果, 表明 LESS 单条带编码吞吐低于 RS, 但编码计算开销相对带宽与 I/O 操作有限. 约 5 分钟.
Exp#B4(网络带宽影响). 预期: 得到与图 5(a) 一致的结果. 表明随网络带宽增加, Clay 受显著 I/O 寻道开销影响, 而 LESS 因小子分组仍有效缩短单块修复时间. 约 2 小时.
Exp#B5(packet 大小影响). 预期: 表明在较小 packet 下, Clay 因处理大量子块产生显著 I/O 开销, 而 LESS 因小子分组保持稳定修复性能. 约 2 小时.
-
Brian Beach. Backblaze Vaults: Zettabyte-scale cloudstorage architecture. https://www.backblaze.com/blog/vault-cloud-storage-architecture/,2019. ↩︎ ↩︎
-
Daniel Ford, François Labelle, Florentina I. Popovici,Murray Stokely, Van-Anh Truong, Luiz Barroso, CarrieGrimes, and Sean Quinlan. Availability in globallydistributed storage systems. In Proc. of USENIX OSDI,2010. ↩︎ ↩︎
-
Cheng Huang, Huseyin Simitci, Yikang Xu, AaronOgus, Brad Calder, Parikshit Gopalan, Jin Li, andSergey Yekhanin. Erasure coding in Windows Azurestorage. In Proc. of USENIX ATC, 2012. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
-
Subramanian Muralidhar, Wyatt Lloyd, Sabyasachi Roy,Cory Hill, Ernest Lin, Weiwen Liu, Satadru Pan, ShivaShankar, Viswanath Sivakumar, Linpeng Tang, and San-jeev Kumar. f4: Facebook’s warm BLOB storage sys-tem. In Proc. of USENIX OSDI, 2014. ↩︎ ↩︎ ↩︎ ↩︎
-
Hakim Weatherspoon and John D. Kubiatowicz. Era-sure coding vs. replication: A quantitative comparison.In Proc. of IPTPS, 2002. ↩︎
-
S. B. Balaji, M. Nikhil Krishnan, Myna Vajha,Vinayak Ramkumar, Birenjith Sasidharan, and P. Vi-jay Kumar. Erasure coding for distributed storage:an overview. Science China Information Sciences,61(100301):100301:1–100301:45, 2018. ↩︎
-
Zhirong Shen, Yuhui Cai, Keyun Cheng, Patrick P. C.Lee, Xiaolu Li, Yuchong Hu, and Jiwu Shu. A surveyof the past, present, and future of erasure coding forstorage systems. ACM Trans. on Storage, 21(1):1–39,2025. ↩︎
-
Chuang Gan, Yuchong Hu, Leyan Zhao, Xin Zhao,Pengyu Gong, and Dan Feng. Revisiting network cod-ing for warm blob storage. In Proc. of USENIX FAST,2025. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
-
Osama Khan, Randal Burns, James Plank, and WilliamPierce. Rethinking erasure codes for cloud file systems:Minimizing I/O for recovery and degraded reads. InProc. of USENIX FAST, 2012. ↩︎
-
Yuchong Hu, Liangfeng Cheng, Qiaori Yao, PatrickP. C. Lee, Weichun Wang, and Wei Chen. Exploitingcombined locality for Wide-Stripe erasure coding indistributed storage. In Proc. of USENIX FAST, 2021. ↩︎ ↩︎
-
Myna Vajha, Vinayak Ramkumar, Bhagyashree Puranik,Ganesh Kini, Elita Lobo, Birenjith Sasidharan, P. VijayKumar, Alexandar Barg, Min Ye, Srinivasan Narayana-murthy, Syed Hussain, and Siddhartha Nandi. Claycodes: Moulding MDS codes to yield an MSR code. InProc. of USENIX FAST, 2018. ↩︎ ↩︎ ↩︎ ↩︎
-
Katina Kralevska and Danilo Gligoroski. An explicitconstruction of systematic MDS codes with small sub-packetization for all-node repair. In Proc. of IEEEDASC/PiCom/DataCom/CyberSciTech, 2018. ↩︎ ↩︎
-
Katina Kralevska, Danilo Gligoroski, Rune E. Jensen,and Harald Øverby. HashTag erasure codes: Fromtheory to practice. IEEE Trans. on Big Data, 4(4):516–529, 2018. ↩︎ ↩︎ ↩︎
-
K. V. Rashmi, Nihar B. Shah, Dikang Gu, HairongKuang, Dhruba Borthakur, and Kannan Ramchandran.A “hitchhiker’s” guide to fast and efficient data recon-struction in erasure-coded data centers. In Proc. ofACM SIGCOMM, 2014. ↩︎ ↩︎ ↩︎
-
Kaicheng Tang, Keyun Cheng, Helen H. W. Chan, Xi-aolu Li, Patrick P. C. Lee, Yuchong Hu, Jie Li, andTing-Yi Wu. Balancing repair bandwidth and sub-packetization in erasure-coded storage via elastic trans-formation. In Proc. of IEEE INFOCOM, 2023. ↩︎ ↩︎ ↩︎ ↩︎
-
Irving S Reed and Gustave Solomon. Polynomial codesover certain finite fields. Journal of the Society for In-dustrial and Applied Mathematics, 8(2):300–304, 1960. ↩︎ ↩︎
-
Konstantin Shvachko, Hairong Kuang, Sanjay Radia,and Robert Chansler. The hadoop distributed file system.In Proc. of IEEE MSST, 2010. ↩︎ ↩︎
-
Xiaolu Li, Keyun Cheng, Kaicheng Tang, Patrick P. C.Lee, Yuchong Hu, Dan Feng, Jie Li, and Ting-Yi Wu.ParaRC: Embracing sub-packetization for repair paral-lelization in MSR-coded storage. In Proc. of USENIXFAST, 2023. ↩︎ ↩︎
-
Xiaolu Li, Runhui Li, Patrick P. C. Lee, and YuchongHu. OpenEC: Toward unified and configurable erasurecoding management in distributed storage systems. InProc. of USENIX FAST, 2019. ↩︎ ↩︎ ↩︎
-
Andreas-Joachim Peters, Michal Kamil Simon, andElvin Alin Sindrilaru. Erasure coding for production inthe EOS open storage system. In Proc. of CHEP, 2019. ↩︎
-
James S. Plank, Jianqiang Luo, Catherine D. Schuman,Lihao Xu, and Zooko Wilcox-O’Hearn. A performanceevaluation and examination of open-source erasure cod-ing libraries for storage. In Proc. of USENIX FAST,2009. ↩︎
-
Alexandros G. Dimakis, P. Brighten Godfrey, YunnanWu, Martin J. Wainwright, and Kannan Ramchandran.Network coding for distributed storage systems. IEEETrans. on Information Theory, 56(9):4539–4551, 2010. ↩︎ ↩︎
-
Yuchong Hu, Henry CH Chen, Patrick PC Lee, andYang Tang. NCCloud: Applying network coding for thestorage repair in a cloud-of-clouds. In Proc. of USENIXFAST, 2012. ↩︎ ↩︎ ↩︎
-
K. V. Rashmi, Preetum Nakkiran, Jingyan Wang, Ni-har B. Shah, and Kannan Ramchandran. Having yourcake and eating it too: Jointly optimal erasure codesfor I/O, storage, and network-bandwidth. In Proc. ofUSENIX FAST, 2015. ↩︎ ↩︎
-
Lluis Pamies-Juarez, Filip Blagojevic, Robert Mateescu, Cyril Gyuot, Eyal En Gad, and Zvonimir Bandic. Open-ing the chrysalis: On the real repair performance ofMSR codes. In Proc. of USENIX FAST, 2016. ↩︎ ↩︎
-
Sage A. Weil, Scott A. Brandt, Ethan L. Miller, DarrellD. E. Long, and Carlos Maltzahn. Ceph: A scalable,high-performance distributed file system. In Proc. ofUSENIX OSDI, 2006. ↩︎
-
S. B. Balaji, Myna Vajha, and P. Vijay Kumar. Lowerbounds on the sub-packetization level of MSR codesand characterizing optimal-access MSR codes achiev-ing the bound. IEEE Trans. on Information Theory,68(10):6452–6471, 2022. ↩︎ ↩︎
-
Saurabh Kadekodi, Shashwat Silas, David Clausen, andArif Merchant. Practical design considerations for widelocally recoverable codes (LRCs). In Proc. of USENIXFAST, 2023. ↩︎ ↩︎
-
Oleg Kolosov, Gala Yadgar, Matan Liram, Itzhak Tamo,and Alexander Barg. On fault tolerance, locality, andoptimality in locally repairable codes. In Proc. ofUSENIX ATC, 2018. ↩︎ ↩︎
-
Maheswaran Sathiamoorthy, Megasthenis Asteris, Dim-itris Papailiopoulos, Alexandros G Dimakis, RamkumarVadali, Scott Chen, and Dhruba Borthakur. XORingelephants: novel erasure codes for big data. In Proc. ofVLDB Endowment, 2013. ↩︎ ↩︎
-
K. V. Rashmi, Nihar B. Shah, Dikang Gu, HairongKuang, Dhruba Borthakur, and Kannan Ramchandran.A solution to the network challenges of data recovery inerasure-coded distributed storage systems: A study onthe facebook warehouse cluster. In Proc. of USENIXHotStorage, 2013. ↩︎
-
James S. Plank and Cheng Huang. Tutorial: Erasurecoding for storage applications. http://web.eecs.utk.edu/~jplank/plank/papers/FAST-2013-Tutorial.html, 2013. ↩︎
-
Hadoop 3.3.4. https://hadoop.apache.org/docs/r3.3.4/, 2022. ↩︎
-
James S. Plank, Scott Simmerman, and Catherine D.Schuman. Jerasure: A library in facilitatingerasure coding for storage applications - version 2.0.Technical Report CS-08-627, 2014. ↩︎
-
Bert Hubert, Jacco Geul, and Simon Séhier. WonderShaper. https://github.com/magnific0/wondershaper, 2012. ↩︎