FAST'26 | 华为云: 基于磁带的高性价比归档云存储 - 设计与部署
Cost-efficient Archive Cloud Storage with Tape: Design and Deployment
本文为 FAST'26 顶会论文,原文链接为 Cost-efficient Archive Cloud Storage with Tape: Design and Deployment
@article{wangcost,
title={Cost-efficient Archive Cloud Storage with Tape: Design and Deployment},
author={Wang, Qing and Yang, Fan and Liu, Qiang and Xiao, Geng and Chen, Yongpeng and Lan, Hao and Chen, Leiming and Chen, Bangzhu and Liu, Chenrui and Bai, Pingchang and others}
}团子导读:深度冷存储与 TapeOBS
深度冷存储的特征
- 写远多于读。 论文给出了生产数据:最大客户的读操作仅占 0.000112%,多位客户甚至从未发起过读请求。这是一种极端的 write-heavy 工作负载。
- 恢复有小时级 SLA。 用户接受数小时的等待——这在普通对象存储中几乎不可想象,但正是这种宽松的时间窗口给了系统做批量调度的空间。
- 数据生命周期长、删除少。 数据一旦写入就要保存数年乃至数十年。用户主动删除极为罕见,多数在过期后自动清理。
- 对 TCO 极其敏感。 存储的是"不得不留"的数据,业务上不会为之付出高额的存储溢价。论文的数据显示,基于磁带的方案 TCO 是 HDD 方案的 1/4.95。
这些特征决定了深度归档存储的设计哲学:一切为成本让路,性能和延迟退居其次。
磁带库与 HDD 的核心区别
磁带库的物理特性带来了一组和 HDD 完全不同工程约束:
1) 存储与访问设备解耦。 HDD 中盘片和磁头是密封在一起的,任何时候都可以读写。磁带库中,1000 盘磁带只配 4 个驱动器——存储介质和读写设备是物理分离的。一个驱动器一次只能服务一盘磁带。这种极端的不对称比(1000:4)是磁带库最核心的约束。
2) 切换代价极高。 将一盘磁带从存储槽装载到驱动器需要约 80 秒——倒带、卸载旧磁带、机械臂搬运、装载新磁带。如果驱动器频繁在不同磁带之间切换(论文称之为"驱动器抖动"),有效带宽会断崖式下降。仅仅在每 23.2GB 数据后做一次切换,有效带宽就已经减半。
3) 顺序访问介质。 HDD 虽然随机读写性能不佳,但至少可以在毫秒级完成寻道。磁带需要正/反向卷带来定位数据,寻道时间远超 HDD。同时,磁带的内部由数百个磁道组(wrap)构成,相邻磁道组的访问方向相反,直觉上按逻辑块顺序访问反而会产生大量不必要的物理寻道。
4) 成本结构不同。 磁带单价低($/GB 比 HDD 低 50% 以上)、寿命长(10 年 vs. 5 年)、闲置零功耗。但驱动器昂贵,带宽受限。可以理解为:存储容量几乎免费,但访问能力是稀缺且昂贵的资源。
这些差异决定了,不能简单地"把 HDD 换成磁带"——需要从架构层面为磁带的物理约束做专门的设计。
本文的核心亮点:应对磁带物理约束的系统设计
围绕磁带的特性展开:
1) 完全异步的磁带池。 TapeOBS 在磁带池之上维护了一个容量约为磁带池 4% 的 HDD 池作为持久化写缓冲。用户写入先落 HDD 池(高可用),然后异步刷入磁带池。用户恢复请求同样异步处理——反正 SLA 是小时级的。这样对磁带池的所有读写都是异步的,解耦了用户请求速率和磁带驱动器的有限带宽。而且方便实现批量调度读写。
2) 专用驱动器。 将 4 个驱动器静态分为写驱动器(2 个)、读驱动器(1 个)和内部驱动器(1 个)。不同任务有不同的访问模式:写是持续顺序追加、读是用户驱动的随机访问、内部操作(GC/一致性检查/EC 修复)通常长时间聚焦同一盘磁带。如果所有驱动器共享所有任务,全部驱动器都会遭受抖动。静态划分后,写驱动器和内部驱动器可以全速运行。
3) 批量纠删码(b-EC)。 TapeOBS 通过在服务层聚合多个对象再做 EC(跨对象 EC),使得多数对象只落在一盘磁带上,其恢复只需一个驱动器。其实在我们的 HDD 大条带 EC 中也可以参考。
4) 面向磁带的本地存储引擎。 在磁带库头节点的 NVMe SSD 上构建了简单的 KV 存储,持久化维护子 PLog 元数据。使用 SCAN 算法对读请求按物理位置排序,减少寻道。
论文还记录了一个有趣的工程发现:磁带驱动器的流量控制问题。驱动器内部有缓冲区,会根据主机提交速率选择写入速度。如果提交速率抖动,驱动器可能错误估计主机速度并选择较低的速度,导致持续的性能下降。通过读取驱动器缓冲区大小来估算驱动器速度,并用速率限制器对齐提交速度。这类问题只有在实际部署中才能遇到,论文公开分享,对后来者很有参考价值。
Append-Only 性质与 Append-Only 系统
现代磁带(如 LTO 系列)是 append-only 的,无法就地更新。原因和 SMR(叠瓦式磁记录)硬盘类似:为了提升存储密度,数据磁道采用叠瓦式重叠排列。就地覆写会破坏相邻磁道的数据。SMR HDD 在消费级市场因这一特性引发了不少争议,但在归档存储场景下,append-only 反而是天然适配的。
append-only 存储在分布式系统中其实是一种被广泛接受的模式。笔者在 RocksDB 存算分离 中也提到,追加写文件系统是很受欢迎的——BigTable、HBase、Spanner 都构建在追加写文件系统之上。追加写牺牲了随机写语义,换取了分布式系统设计和容灾机制的简化。
TapeOBS 天然利用了这种 append-only 特性。PLog(持久化日志)作为基本存储单元也是 append-only 的:创建、追加、封存,之后变为不可变。日志结构化写入使得驱动器可以持续向同一盘磁带顺序追加,最大限度减少了驱动器切换和寻道。磁带的分区机制则提供了有限的独立追加点,放宽了纯顺序写的约束。
append-only 天生也带来的垃圾回收(GC)问题(这个缺点其实和磁带无关,只是磁带介质大幅度放大了 GC 的影响)。HDD 上的 GC 涉及的是磁盘读写,而磁带上的 GC 还要面临驱动器切换和卷带寻道的额外开销。TapeOBS 结合业务特性通过基于生命周期的数据分组缓解了这个问题。
导读小结
这是一篇极具实际意义和工程价值的系统论文,详细介绍非常多磁带深度冷存储的细节。对正在构建深度冷存储、混合存储的读者非常有实践意义。设计重度 GC 存储系统的开发者也可以参考。非常推荐阅读。
以下是论文全文翻译。
摘要
TapeOBS 是华为云提供的一项归档存储服务, 通过利用磁带来存储海量归档数据, 实现了高性价比. 尽管磁带具有较低的总拥有成本(TCO), 但其固有特性(例如磁带库中驱动器数量有限)在构建大规模分布式存储系统时带来了独特的挑战. 为应对这些挑战, 我们采用了整体性的设计方法来构建 TapeOBS. 在上层架构方面, 我们引入了完全异步的磁带池, 支持以批量方式进行数据调度和纠删码编码, 以适配磁带硬件的特性. 在磁带库内部, 我们设计了面向磁带的本地存储引擎, 并采用了专用驱动器等技术来优化性能. TapeOBS 于 2022 年底开始逐步上线, 并于 2024 年正式对外提供客户服务. 截至本文撰写时, TapeOBS 已存储了数百 PB 的原始用户数据.
1 引言
人类正以前所未有的速度产生数据, 据估计 2024 年每天生成的数据量达 4.0274 亿 TB1. 虽然其中大部分数据处于活跃使用状态, 但仍有相当大的比例——如医学影像、备份文件、视频素材和日志——虽然很少被访问, 却必须长期保留. 这一需求使得归档存储不可或缺. 因此, 许多云服务提供商, 包括华为云2、AWS3、GCP4和阿里云5, 都提供了归档存储服务, 专注于长期保存和成本效率, 为管理海量但极少访问的数据提供可扩展的解决方案.
本文介绍了 TapeOBS 的设计与部署. TapeOBS 是一种基于磁带的归档存储服务, 向客户暴露对象接口. 在 TapeOBS 之前, 华为云已有基于 HDD 的归档存储服务. 为了追求更高的性价比, 我们旨在利用磁带——一种古老但仍在不断演进的存储技术——为客户提供更低成本的归档存储服务. 与 HDD 相比, 磁带具有更低的总拥有成本(例如价格低 , 使用寿命长 ), 更少的 排放6, 以及更清晰的技术发展路线图7.
然而, 构建 TapeOBS 并非简单地用磁带替换 HDD. 从物理层面看, 一个分布式的磁带存储系统由一组磁带库组成. 一个磁带库通常容纳数千盘磁带, 并呈现出独特的特征. 首先, 磁带库将磁带(存储数据)与驱动器(读写磁带数据)解耦, 并且其驱动器与磁带的数量比很低. 例如, 在 TapeOBS 中, 一个磁带库包含 1000 盘磁带但仅有 4 个驱动器, 每个驱动器可提供 360MB/s 的带宽. 其次, 将磁带挂载到驱动器的过程非常耗时(在我们的平台上约需 80 秒), 涉及倒带和卸载上一盘磁带、装载目标磁带以及机械臂的物理移动等操作. 如果一个驱动器频繁地在不同磁带之间切换(我们称之为驱动器抖动), 则无法充分发挥其原始性能. 最后, 虽然磁带支持随机读取, 但需要通过正/反向卷带来定位数据, 从而产生可观的寻道时间. 上述对磁带的认识促使我们采用整体性方法来设计 TapeOBS.
在上层架构方面, TapeOBS 引入了完全异步的磁带池, 这意味着对磁带的所有读写操作都是异步的(即不需要立即执行). 具体而言, 除磁带池外, TapeOBS 还维护了一个小型 HDD 池, 其容量在生产环境中约为磁带池的 . HDD 池作为数据的临时暂存区. 对于用户写入, TapeOBS 首先以高可用方式将数据推入 HDD 池, 然后异步地将数据刷入磁带池. 通过这种方式, TapeOBS 能够应对突发工作负载, 因为 HDD 池具有比磁带池更大的聚合写入带宽. 对于用户读取, 利用恢复归档对象(restore)的小时级 SLA, 在收到恢复请求后, TapeOBS 异步地将对象从磁带池复制到 HDD 池. HDD 池中的对象随后即可服务用户的读取请求.
这种异步性带来了一个关键优势: 我们可以以批量方式调度大量数据进出磁带池, 以适配磁带硬件的特性. 首先, TapeOBS 根据对象的生命周期对 HDD 池中的对象进行分组, 将具有相似生命周期的对象通过日志结构化写入方式迁移到同一盘磁带上. 这减轻了磁带池的垃圾回收(GC)开销, 因为同一盘磁带上的对象很可能被同时删除. 如果没有 HDD 池作为持久化写缓冲, 在磁带上执行基于生命周期的数据放置将非常困难. 困难在于: 驱动器数量有限且驱动器切换耗时, 使得为每个生命周期分组维护一盘可立即写入的磁带不切实际. 为容忍磁带故障, TapeOBS 采用了批量纠删码(b-EC), 它将多个对象聚合形成跨对象条带, 并分发到不同的磁带库. b-EC 降低了一个对象横跨多个磁带库的概率, 从而减少了恢复该对象所需的驱动器数量. 其次, 对于恢复请求, 我们对其进行重排序, 使相邻请求指向相同的目标磁带. 通过这种方式, 磁带库将接收到一串具有物理局部性的请求流, 从而减轻驱动器抖动并降低寻道时间.
在磁带库内部, TapeOBS 设计了面向磁带的本地存储引擎. 通过利用每个磁带库中安装的两块 NVMe SSD, 该存储引擎消除了磁带上的随机元数据访问. 具体而言, 我们构建了一个简单的基于 SSD 的键值存储, 持久化维护 PLog(一种存储对象的基本单元)的元数据. 这样, 在获取磁带上的对象时, 我们可以在不触碰磁带的情况下获得其物理位置. 为容忍 SSD 故障, 我们使用了两种技术: 1) 在磁带上创建元数据分区, 并在磁带写满时将元数据转储到该分区; 2) 为磁带中每个 4KB 数据块标记 DIF(数据完整性字段), 使数据具备自恢复能力.
为优化磁带访问性能, 本地存储引擎还包含一个磁带库调度器, 对 I/O 请求进行流量控制和重排序. 在调度器之外, TapeOBS 还采用了专用驱动器技术, 将驱动器静态分配给不同任务, 以避免因任务干扰导致的驱动器抖动.
TapeOBS 于 2022 年底开始逐步上线, 并于 2024 年正式对外服务客户. 截至撰稿时, TapeOBS 已存储了数百 PB 的原始用户数据. 我们展示了 TapeOBS 在生产环境中的工作负载特征和性能. 此外, 我们还揭示了 TapeOBS 所经历的磁带库故障情况.
*共同第一作者. †通讯作者: Jiwu Shu ([email protected]) 和 Huatao Wu ([email protected]).
2 背景与动机
本节首先介绍磁带和磁带库的背景知识(§2.1). 然后, 介绍云端归档存储服务(§2.2). 最后, 从 TCO 角度分析我们为何在现有基于 HDD 的归档存储之外, 还要构建基于磁带的归档存储服务(§2.3).
2.1 磁带与磁带库
磁带. 磁带是一种早在 20 世纪 50 年代初期就被引入计算机系统的存储介质8. 从物理结构上看, 磁带由一条柔性塑料带基组成, 表面涂覆一层磁性材料, 通常以磁带盒9的形式封装. 这种结构决定了磁带是顺序访问的: 磁带驱动器通过正向和反向卷带, 以线性顺序存取数据(使用读/写磁头).
磁带技术在近几十年仍在持续演进. 线性磁带开放标准(LTO)1011由 HPE、IBM 和 Seagate 联合创建, 是一种广泛使用的开放磁带标准. LTO 的最新一代——LTO-10——于 2025 年 5 月发布. 一盘 LTO-10 磁带可提供 30TB 容量和 400MB/s 的最大访问速度. IBM 359212是 IBM 开发的企业级磁带格式和驱动器系列. 最新的 IBM 3592 产品 TS1170 于 2023 年发布, 具备 50TB 容量和 400MB/s 访问速度.
这些现代磁带集成了一系列先进的硬件特性, 包括: ❶ 加密: 使用 AES 等加密算法保护磁带上的数据; ❷ 压缩: 利用无损压缩算法减小数据体积, 例如 LTO-10 磁带标称 2.5:1 的压缩比(因此可存储 75TB 压缩数据); ❸ 分区: 将磁带空间划分为多个可独立写入的分区.
磁带的存储单元是块, 其大小可设为磁带允许的值(如 64KB). 上层软件可使用 ⟨分区 ID, 块 ID⟩ 对来访问磁带上的数据. 为简化使用, 可以通过 LTFS13 等专用文件系统来管理磁带.
现代磁带(如 LTO 磁带)是仅追加(append-only)的, 这意味着无法对其进行就地更新. 其原因与 SMR HDD14 等存储设备类似: 这些磁带采用叠瓦式(shingling)重叠数据磁道11以实现更高的存储密度; 因此, 就地更新会破坏相邻数据. 前述分区机制可以放宽仅追加约束. 分区之间保留了保护区域, 使得对一个分区的写入不会影响另一个分区. 这样, 每个分区拥有独立的追加点.
磁带库. 使用磁带库是企业或数据中心部署磁带存储资源的常见方式. 如图 1 所示, 一个典型的磁带库主要包括: 容纳数据的大量磁带盒, 可访问磁带数据的多个驱动器, 以及一个在存储槽和驱动器之间搬运磁带盒的机械臂. 一个磁带库可以存储数 PB 到数百 PB 的数据. 例如, IBM Diamondback 磁带库15可容纳 1584 盘磁带盒, 使用 LTO-10 磁带时可提供 46PB 的未压缩存储容量.
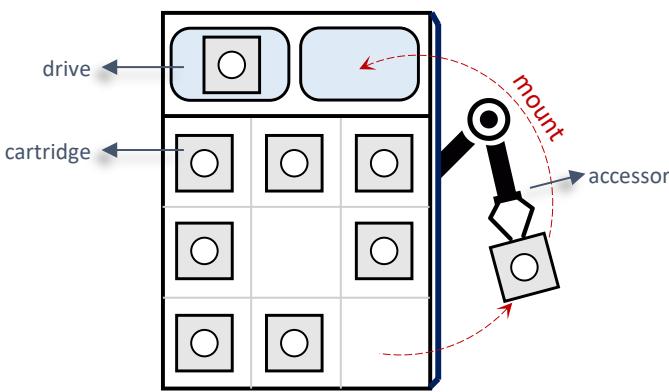
图 1: 磁带库示例. 本图展示了磁带库中的组件, 包括磁带驱动器、磁带盒和机械臂; 图中机械臂正在将一盘磁带盒装载到驱动器上.
尽管可放置大量磁带盒, 磁带库却仅配备有限数量的驱动器(例如 4 个). 这种不对称是一把双刃剑. 一方面, 由于驱动器远比磁带昂贵, 这大幅降低了磁带库的成本. 另一方面, 它造成了性能瓶颈: 驱动器限制了磁带库所能提供的峰值带宽. 此外, 将一盘磁带装载到驱动器耗时可观(例如从数秒到数十秒): 在机械臂将目标磁带移至驱动器并完成装载之前, 驱动器需要先倒带并卸载上一盘磁带.
2.2 云端归档存储服务
企业、政府和个人产生的数据量正以前所未有的速度增长. 其中大量数据极少被访问, 但仍需出于未来参考、法律原因或合规要求而予以保留. 典型的例子包括医学影像数据、备份数据、视频素材和日志. 归档存储系统专为此类工作负载而设计, 通常使用 HDD 或磁带来存储海量数据. 大多数云厂商都提供归档存储服务, 如华为云2、AWS3、GCP4和阿里云5. 与本地部署方案相比, 基于云的归档存储服务享有云的固有优势, 如自动化生命周期管理、几乎无限的可扩展性以及全球可访问性.
华为云主要通过其对象存储服务(OBS)2提供归档存储. 用户将需要归档的数据以对象形式上传到 OBS. 与标准对象不同, 归档对象不允许实时检索. 用户必须首先向归档对象提交恢复请求. 请求完成后, 对象的临时副本将被创建可用, 用户随后可发送获取请求来访问该临时副本的内容. 例如, TapeOBS 为恢复请求提供两个定价层级: ① 快速恢复(Expedited restore): 3-5 小时; ② 标准恢复(Standard restore): 5-12 小时.
2.3 构建 TapeOBS 的动机
在构建 TapeOBS 之前, 华为云已有基于 HDD 的归档存储服务. 我们希望为用户提供更具性价比的归档存储服务, 因此将目光投向了磁带. 在性价比方面, 磁带相较 HDD 具有明显优势. 首先, 磁带的单位 GB 成本更低: 例如, 根据 diskprices.com 网站数据, LTO-8/9 磁带的单位 GB 价格比 HDD 低 以上. 其次, 磁带的使用寿命长于 HDD(10 年 vs. 5 年), 这意味着使用磁带时硬件更换及伴随的数据迁移频率更低. 第三, 基于磁带的存储系统比基于 HDD 的系统能耗低得多; 此外, 当磁带盒位于存储槽中(而非驱动器中)时, 无需消耗电力. 最后, 磁带提供更高的存储密度, 使我们能够节省大量数据中心地面空间(在我们的场景中节省了 ).
表 1 给出了磁带和 HDD 的 TCO 对比. 我们以 100PB 初始数据量和 年增长率为假设, 计算了 10 年 TCO. 基于磁带的方案具有 更低的 CapEx(资本支出), 主要包括硬件采购成本; 以及 更低的 OpEx(运营支出), 主要由运维、维护和能耗成本构成. 综合来看, 基于磁带的方案可实现 更低的 TCO.
| 指标 | 比值 |
|---|---|
| CapEx_hdd / CapEx_tape | 2.68× |
| OpEx_hdd / OpEx_tape | 16.11× |
| TCO_hdd / TCO_tape | 4.95× |
表 1: 磁带与 HDD 的 TCO 对比. TCO 为 CapEx 与 OpEx 之和.
除性价比外, 磁带还有两个促使我们构建归档存储服务的优势. 首先, 使用磁带可以显著减少 排放6, 这与华为云的碳中和目标一致. 其次, 磁带拥有清晰的技术路线图7: 例如, 从 2024 年到 2034 年, 单盘磁带盒的容量将以年均 的速率增长. 这使我们有信心对该技术进行长期投入.
3 TapeOBS 概述
TapeOBS 是一种面向磁带设计并部署在华为云上的归档存储服务. 本节主要描述 TapeOBS 的架构和工作流程.
3.1 持久化日志 (PLog)
在描述 TapeOBS 架构之前, 我们首先介绍 PLog——华为云存储基础设施中的一个关键概念. PLog 是存储数据的基本单元, 且为仅追加的. 我们可以调用若干接口来操作 PLog: 首先以指定最大容量创建一个新的 PLog, 然后向其追加数据或通过偏移量读取数据; 当我们封存(seal)该 PLog 后, 它变为不可变的, 不再接受追加操作. PLog 具有高可用性, 因为它内部采用了副本或纠删码. 每个 PLog 拥有一个 64 位唯一标识符, 本文称之为 plog-id.
3.2 架构
图 2 展示了 TapeOBS 的架构, 由四个关键组件构成:
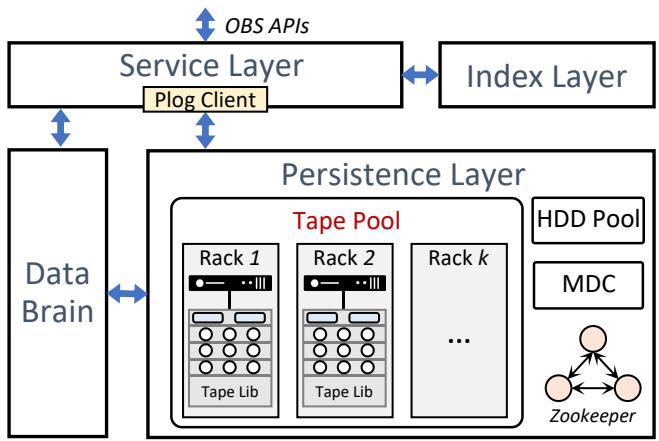
图 2: TapeOBS 的架构. 包括服务层、索引层、持久化层和 DataBrain.
服务层(Service Layer). 服务层提供 OBS API 并预处理用户请求, 包括域名解析、认证和流量控制. 该层内嵌一个 PLog-Client, 用于与持久化层交互, 将对象数据写入/读出 PLog.
索引层(Index Layer). 索引层将对象语义转换为 PLog 语义. 具体而言, 它维护从对象 ID 到一组三元组 ⟨plog-id, offset, size⟩ 的映射. 该映射存储在基于 LSM-Tree 的键值存储中. 我们将映射分片并复制到一个服务器集群, 以实现高可扩展性和高可用性.
持久化层(Persistence Layer). 持久化层使用 PLog 抽象将数据存储在磁带中, 并向其他层暴露 PLog 接口. 此外, 它通过分布式纠删码为 PLog 提供高可用性. 持久化层不感知对象语义, 仅处理 PLog. 持久化层主要由三部分组成:
- 磁带池(Tape Pool). 磁带池负责持久且可靠地维护 PLog. 磁带池由一组磁带机架组成. 每个机架包含一台头节点服务器和一个磁带库, 两者通过光纤通道连接. 头节点服务器通过运行本地存储引擎来管理磁带库中的磁带. 头节点服务器配备两个 12 核 CPU、128GB DRAM 和两块 3TB NVMe SSD 用于数据缓存. 头节点服务器通过两块 25Gbps NIC 连接到两台 ToR 交换机. 值得注意的是, 与标准服务器机架不同, 多个磁带机架(例如 14 个)共享两台 ToR 交换机. 表 2 展示了我们使用的磁带库配置, 配备 4 个磁带驱动器(每个驱动器可提供 360MB/s). 磁带库提供总计 10.24PB 的未压缩容量. 需要指出的是, 我们目前未使用磁带库的内置压缩功能. 原因有二: (1) 大多数用户数据已加密, 导致压缩比很低; (2) 对于未加密数据, 我们已在服务层进行压缩, 这也有助于减少到磁带库的网络流量.
| 参数 | 值 |
|---|---|
| 磁带盒数量 | 1000 |
| 每盘磁带盒容量 | 10742 GB |
| 总容量 | 10.24 PB |
| 驱动器数量 | 4 |
| 每驱动器带宽 | 360 MB/s |
表 2: TapeOBS 中磁带库的配置.
-
MDC(元数据控制器). MDC 管理磁带池的关键配置, 包括拓扑信息、健康磁带集合, 以及一个称为分区视图的表. 这些配置被同步到一个 ZooKeeper 集群16. MDC 通过心跳检测来监控磁带机架的健康状态. 分区视图对于 PLog 的数据分布至关重要. 分区视图中的每个条目是一个键值对, 其中键为分区 ID(即 pt-id), 值为来自不同机架的一组磁带; 这意味着这些磁带将组成一个纠删码组. PLog 与其分区之间存在以下关系: , 其中 N 是一个预定义值. 利用该关系, MDC 还执行另一项任务: 为服务层分配 plog-id, 并确保关联的 PLog 被存储在指定的分区中.
-
HDD 池(HDD Pool). HDD 池用作数据的临时暂存区. 当用户对归档对象发起恢复请求(参见 §2.2)时, 对象从磁带池复制到 HDD 池. 用户通过获取请求获得这些对象后, HDD 池上的临时副本将被释放. 为简化开发, 我们的 HDD 池直接复用了华为云成熟的现成 HDD-based OBS 系统, 该系统提供具有高持久性和高可用性的对象接口. 磁带池与 HDD 池的容量比约为 100:4.
DataBrain. DataBrain 负责调度 TapeOBS 中的非实时任务, 如恢复任务和垃圾回收任务. 服务层和持久化层向 DataBrain 上报统计信息.
3.3 TapeOBS 中的工作流程
下面我们通过示例描述写入和读取对象的工作流程, 以展示 §3.2 中各组件之间的交互方式. 假设 EC 配置为 , 即 4 个数据块和 2 个校验块:
写入一个 4MB 对象. ❶ 服务层通过调用 PLog-Client 创建一个 PLog, 返回 plog-id 等于 0xaabb. 注意 PLog-Client 向 MDC 请求分配 plog-id. ❷ 服务层调用 PLog 追加接口, 传入 4MB 对象数据和 plog-id=0xaabb 作为参数. ❸ PLog-Client 使用 plog-id=0xaabb 计算 pt-id 的值, 如图 3 所示, 等于 0xbb. ❹ PLog-Client 查询分区视图, 获得关联 EC 组中的磁带: tape-A – F; 这些磁带位于不同的磁带机架中. 注意分区视图由 MDC 维护, 但可被缓存在 PLog-Client 中. ❺ PLog-Client 将对象均匀分割为四个 1MB 数据块(图中的 D0 – D3), 并生成两个校验块(P0 和 P1); 然后分别分发到 tape-A – F. ❻ 各磁带机架中的本地存储引擎将这些块存储在子 PLog(sub-PLog)17中. 此处为简化起见, 省略了 NVMe SSD 的数据缓存. 每个存储引擎记录本地子 PLog 的物理地址, 以 plog-id(即 0xaabb)为索引. ❼ 当 PLog-Client 收到这六个磁带机架的完成消息后, 它将 PLog 追加调用(步骤 ❷)的结果返回给服务层. 结果包含对象在 PLog 中的逻辑偏移量(我们称之为 F). F 等于 , 其中 4 是数据块数量, k 是数据块在子 PLog 中的偏移量. ❽ 最后, 服务层将映射 {对象 ID → ⟨0xaabb, F, 4MB⟩} 插入索引层. 服务层可以继续向 PLog 0xaabb 追加新对象, 直到达到其最大容量.
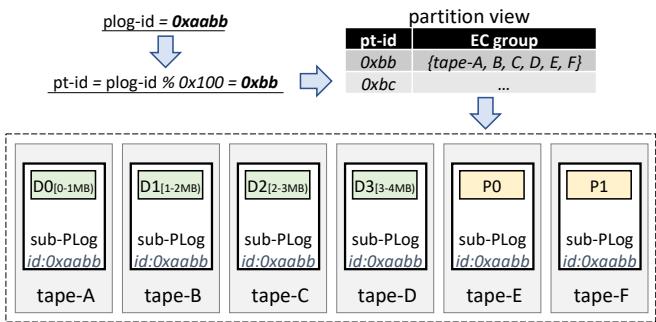
图 3: 向 TapeOBS 写入一个 4MB 对象的示例. 假设纠删码配置为 4+2: 4 个数据块和 2 个校验块. 每个 PLog 由六个子 PLog 组成, 分别存储在位于六个不同磁带机架中的磁带上.
读取对象. 要读取一个对象, 用户须先向 TapeOBS 发起恢复请求. 该请求将由 DataBrain 调度并转发给服务层. ① 服务层以对象 ID 为键查询索引层, 获得三元组 ⟨plog-id=0xaabb, offset=F, size=4MB⟩. ② 服务层调用 PLog 读取接口; PLog-Client 计算 pt-id 并根据分区视图获取 EC 组. ③ PLog-Client 向 tape-A、B、C 和 D 发送请求, 要求从子 PLog(plog-id=0xaabb)中以偏移量 F/4 返回 1MB 数据. ④ 各磁带机架中的本地存储引擎定位子 PLog 的物理地址, 然后读取数据. ⑤ 服务层接收到四个数据块后, 将其拼接成完整对象, 并将对象暂存到 HDD 池.
内部操作. 除了响应用户请求的对象写入和读取外, TapeOBS 还涉及一些内部操作:
-
一致性检查(Consistency Checking). 与许多大规模存储系统18192021类似, TapeOBS 使用校验和保护用户数据: 每 4KB 数据附带一个 4B 校验和, 每次读取数据(从 DRAM、SSD 或磁带)时都会进行验证. 由于在归档存储工作负载中大多数对象长期不被访问, TapeOBS 采用后台服务执行一致性检查, 从磁带读取数据并执行两项操作: 1) 验证每 4KB 数据的校验和; 2) 为每个 PLog 计算 EC 校验块, 并检查其是否与磁带上存储的一致. 通过此机制, 我们可以检测由硬件问题和软件缺陷导致的数据损坏, 例如因 CPU SDC(静默数据损坏)2223引起的错误 EC 计算.
-
EC 修复. 在检测到磁带损坏或数据完整性问题时, TapeOBS 将执行 EC 修复以重建数据. 这涉及从 EC 组中存活磁带读取数据, 并将恢复的数据写入新磁带.
-
垃圾回收(GC). 随着对象被删除, 磁带中包含过期数据. 磁带的仅追加特性使得必须通过垃圾回收来回收空间. TapeOBS 以 EC 组(即一个分区)为单位执行 GC. 在选择一个 EC 组进行 GC 时, TapeOBS 读取有效对象, 将其重新写入系统, 并释放 EC 组中的磁带.
4 TapeOBS 的关键设计
我们已在 §3 中描述了 TapeOBS 的概述, 使读者能够理解其工作原理. 本节将进一步阐述 TapeOBS 的若干关键设计, 重点介绍这些设计如何在充分考虑磁带特性的前提下优化 TapeOBS 的性能.
4.1 设计原则
TapeOBS 遵循三个核心设计原则.
1) 最小化磁带库内的驱动器抖动. 在磁带库中, 驱动器数量远少于磁带盒数量. 因此, 如果要访问一盘位于存储槽中的磁带, 驱动器需要倒带并卸载旧磁带、装载新磁带, 最终执行寻道到目标地址. 此外, 机械臂还需在存储槽和驱动器之间搬运这两盘磁带. 整个过程在我们的硬件平台上约耗时 80 秒. 如果一个驱动器频繁切换以服务不同的磁带——即我们所说的驱动器抖动——则难以充分发挥驱动器的原始性能. 例如, 即使在每访问 23.2GB(即 )连续数据后才执行一次驱动器切换, 有效驱动器带宽也将下降一半. 因此, 我们提出了专用驱动器(§4.2)和批量纠删码(§4.3), 两者均旨在最小化磁带库内的驱动器抖动.
2) 避免磁带内的随机读取. 即使我们能保证一个驱动器在较长时间内只访问某一盘磁带, 仍需进一步避免随机读取. 这是因为随机读取会导致大量时间耗费在寻道操作(即正/反向卷带到指定位置)上. 例如, 在 TapeOBS 中, 对象的写入/读取涉及定位子 PLog 的物理位置, 如果处理不当, 可能导致磁带上的大量随机元数据访问. 此外, 考虑到磁带由多个磁道组(wrap)构成的内部结构, 减少寻道时间并非易事. 我们通过设计高效的面向磁带的本地存储引擎(§4.5)来遵循此原则, 该引擎避免了磁带上的细粒度元数据操作, 并通过调度和流量控制优化数据操作.
3) 使对磁带池的读写异步化. 前两个原则旨在充分挖掘磁带驱动器的性能潜力. 然而, 我们仍面临磁带池固有的性能限制: 由于驱动器数量有限, 聚合带宽受限. 如果磁带池同步服务用户请求, 这一受限带宽将直接暴露给用户: 例如, 对象的 put 请求将遭受低吞吐量. 为解决此问题, TapeOBS 将恢复操作使用的 HDD 池复用为持久化写缓冲, 并异步地将数据从 HDD 池刷入磁带池(§4.4). 这样, 对磁带池的所有读取(即恢复)和写入都是异步的. 这种异步性还为 TapeOBS 带来一个关键优势: 我们可以批量调度大量数据进出磁带池, 以实现特定目标, 例如 1) 通过基于生命周期的分类降低 GC 开销, 2) 通过重排序恢复请求减少驱动器抖动和寻道.
4.2 专用驱动器
TapeOBS 采用专用驱动器来减少驱动器抖动. 具体而言, 我们将磁带库中的驱动器静态划分为三组: 1) 写驱动器, 服务对象写入; 2) 读驱动器, 服务对象读取; 3) 内部驱动器, 服务内部操作, 包括一致性检查、EC 修复和垃圾回收. 这一方案背后的原因是这些操作具有不同的访问模式. 对于写操作, 我们可以持续向一盘磁带追加对象数据, 直到其写满(即日志结构化方式). 对于读操作, 请求由用户发起因而不可预测, 不可避免地需要访问不同的磁带. 对于内部操作, 驱动器通常长时间专注于同一盘磁带. 如果每个驱动器同时服务所有操作——我们称之为共享驱动器——则所有驱动器都将遭受驱动器抖动. 相比之下, 使用专用驱动器, 写驱动器和内部驱动器能够在无驱动器抖动的情况下以全速运行.
接下来需要确定各类驱动器的数量. 我们选择两个驱动器作为写驱动器、一个作为读驱动器、一个作为内部驱动器(回顾: 我们的磁带库各有四个驱动器). 此配置优先保障写请求而非读请求, 但这是合理的, 因为归档存储工作负载通常包含远多于读操作的写操作. 表 3 展示了 TapeOBS 中专用驱动器的配置. 需要注意的是, 当磁带库写满后, 两个写驱动器将转换为一个读驱动器和一个内部驱动器.
| 驱动器类型 | 数量 | 服务的操作 |
|---|---|---|
| 写驱动器 | 2 | 用户对象写入 |
| 读驱动器 | 1 | 用户对象读取 |
| 内部驱动器 | 1 | 一致性检查、EC 修复、GC |
表 3: TapeOBS 中的专用驱动器.
将写驱动器固定到磁带. 为使每个驱动器始终向同一盘磁带追加数据, MDC 以如下方式分配 plog-id: 根据 plog-id 与 pt-id 之间的关系(回顾 §3.2), MDC 保证对于每个磁带库, 仅有两个(即写驱动器的数量)活跃分区包含该磁带库, 并分配属于这两个分区的 plog-id. 这样, 写驱动器将持续向一盘磁带追加数据直到其写满, 然后切换到下一盘.
讨论. 专用驱动器的主要局限性在于动态工作负载下潜在的资源利用率不足. 我们可以通过在粗粒度(例如每小时)上根据工作负载重新分配驱动器来增强适应性. 这种策略可以提高驱动器利用率, 同时仍能避免过度的驱动器抖动.
4.3 批量纠删码
在 TapeOBS 中, 磁带机架被视为独立的故障域. TapeOBS 利用纠删码将数据跨不同磁带机架存储, 以确保故障容忍和高可用性. 与副本相比, EC 有两个显著优势. 首先, EC 具有低存储冗余: 对于 的 EC 配置——m 个数据块和 n 个校验块——它可以容忍 n 个故障, 存储冗余为 , 通常小于 1.50. 低存储冗余可以节省大量存储空间, 考虑到归档数据的巨大体量, 这一点尤为重要. 其次, 低存储冗余也意味着写入的数据更少, 从而减少磁带驱动器的写入带宽消耗. 在固定 n(即容错能力)的条件下, 我们希望为 TapeOBS 选择较大的 m, 以获取更多 EC 带来的收益.
然而, 在 TapeOBS 的早期版本中, 较大的 m 会导致对象读取时更严重的驱动器抖动. 回顾图 3: 服务层将对象写入转换为 PLog 追加, 将数据块和校验块分发到不同的磁带机架以实现高可用性. 因此, 读取该对象需要从 m 盘磁带中读取数据, 消耗可观的驱动器资源. 当许多位于不同分区(即 EC 组)上的对象需要被读取时, 这不可避免地引入大量的驱动器切换.
从原理上讲, 解决方案很简单: 使用跨对象 EC(inter-object EC)而非对象内 EC(intra-object EC), 使每个对象仅位于一盘磁带上. 然而, 这在工程实现上存在挑战. 直觉上, 我们需要在持久化层实现跨对象 EC: 让持久化层生成包含不同对象的 EC 条带. 但持久化层不感知对象语义, 将对象语义注入其中需要大规模代码重构, 并且会破坏层间清晰的边界.
TapeOBS 采用了一种精巧的方法——批量纠删码(b-EC)——来实现跨对象 EC. 其核心思想是让服务层通过单次 PLog 追加调用聚合多个对象. 图 4 展示了一个示例, EC 配置为 . 服务层首先在内存中聚合五个对象(共 1.5GB). 然后, 创建一个最大容量为 1.5GB 的 PLog. 最后, 调用一次 PLog 追加接口追加聚合后的 1.5GB 数据, 并封存该 PLog. 通过这种方式, 包含多个对象的 1.5GB 数据被水平切分为 4 个数据块, 分布到不同的磁带上. 如图所示, 对于 Object 1-4, 每个对象仅存在于一盘磁带上; 对于 Object 5, 其数据跨越两盘磁带. 因此, 读取这些对象将使用更少的磁带驱动器, 触发更少的驱动器切换. 为实现 b-EC, 我们仅在服务层添加了简单的聚合功能, 并修改了 PLog-Client 中 PLog 偏移量与子 PLog 偏移量之间的转换逻辑.
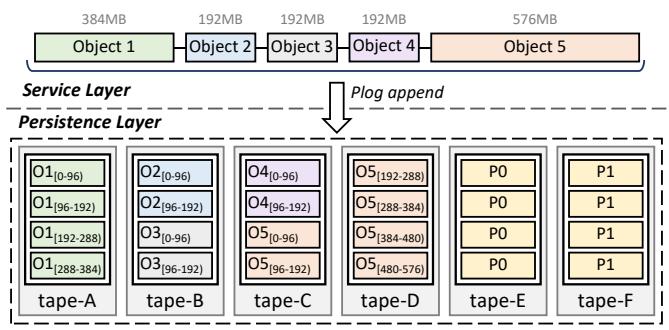
图 4: 批量纠删码(b-EC)示例. 假设 EC 配置为 4+2: 4 个数据块和 2 个校验块(在 Tape-E 和 F 中). 六盘磁带位于六个不同的磁带机架中. 通过 b-EC, TapeOBS 中的一个对象被存储在更少的磁带上, 从而在读取时减少驱动器抖动.
b-EC 有一个缺点: 它会增加降级读所需的数据量. 当一盘磁带故障时, TapeOBS 执行 EC 修复. 在 EC 修复过程中, 如果需要读取故障磁带上的对象, 必须利用其他存活数据进行重建. 对于大小为 S 的对象, b-EC 使重建所需的数据量从 S 增加到 . 考虑到 b-EC 的收益和降级读的相对低频率, 我们认为这是可以接受的.
通过 b-EC, TapeOBS 部署了 的 EC 配置, 冗余率为 1.17. TapeOBS 使用华为自研的低密度纠删码(LDEC)算法, 这是一种基于 XOR 和伽罗瓦域乘法的 MDS(最大距离可分)阵列码.
4.4 异步磁带池与批量调度
如 §3.2 所述, 每个磁带池配有一个 HDD 池. 当用户向 TapeOBS 发起恢复请求时, 关联对象被临时复制到 HDD 池, 以服务后续的获取请求. 考虑到恢复操作的小时级 SLA(回顾 §2.2), 我们可以异步调度恢复请求, 以减少磁带驱动器的抖动和寻道.
我们进一步将 HDD 池复用为写请求的持久化写缓冲: 用户的写请求先由 HDD 池吸收, 然后再消化到磁带池. 这样, 我们获得了如图 5 所示的完全异步磁带池: 对其所有写入和读取都是异步的. 这种完全异步设计带来两个优势. 首先, 它能够应对突发工作负载, 因为 HDD 池虽容量较小但具有更大的聚合带宽. 需要注意的是, HDD 池也使用相同的 EC 配置以提供高可用性. 其次, 它支持两个池之间的批量调度. 具体而言, 由于对磁带的访问是非实时的, 我们可以根据调度策略对大量对象进行分类、分组和重排序, 实现高效的磁带批量数据传输. TapeOBS 使用 DataBrain 作为批量调度的控制平面. 下面分别描述 TapeOBS 如何对对象恢复和写入执行批量调度.
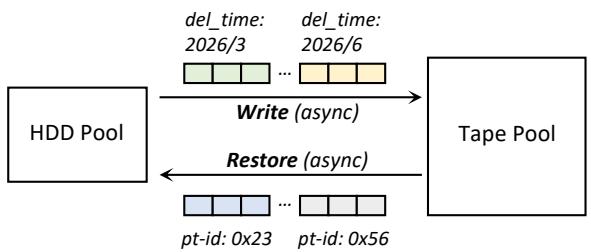
图 5: 具有批量调度的完全异步磁带池. 对于对象恢复, 我们批处理和排序请求以创建磁带上的顺序访问模式, 减轻驱动器抖动. 对于对象写入, 将具有相似生命周期的数据分组并写入相同的磁带, 降低垃圾回收开销.
对象恢复的批量调度. 对于恢复请求, 批量调度的目标是在不违反 SLA 的前提下减少驱动器抖动和寻道. 每个恢复请求首先被转换为一组任务 ⟨ddl, pt-id, plog-id, offset, size⟩, 其中 ddl 是恢复请求的截止时间(根据 SLA 计算, 以小时粒度表示), pt-id 由 plog-id 计算得出. 注意这些任务被持久化存储以防止故障. DataBrain 按如下方式调度这些任务: 1) 将所有具有最小 ddl 的任务收集到一个待处理集合中; 2) 根据 pt-id 对待处理集合中的任务分组; 3) 在每个组内, 按照 ⟨plog-id, offset⟩ 对的递增顺序排序; 4) 逐组将待处理集合中的任务分发到磁带池. 这样, 每个磁带机架将接收到一串具有物理局部性的读请求流, 从而减轻驱动器抖动(通过将同一分区的任务分组)和降低寻道时间(通过使用偏移量对同一 PLog 中的任务排序).
对象写入的批量调度. 对于写请求, 批量调度的目标是将具有相似生命周期的对象存储在同一盘磁带上, 从而降低 GC 开销. 目前, 用户可以在 TapeOBS 中为桶或对象设置过期时间; 桶是存储对象的容器(类似于文件系统中的目录). 对于一个对象, 如果自其最后更新以来的时间超过过期时间, 它将被自动删除. 利用过期时间, 我们可以估算对象的删除时间. DataBrain 根据删除时间对 HDD 池中的对象进行分组(以 3 个月为分组粒度). 然后, 将同一组中的对象批量写入磁带池. 通过这种方式, TapeOBS 可以确保一盘磁带包含具有相似生命周期的对象. 因此, GC 开销将得到缓解, 因为一盘磁带上的数据很可能被同时删除, 大大减少了 GC 期间读取和重写有效数据的量. 如果没有 HDD 池作为持久化写缓冲, 在磁带上执行基于生命周期的数据放置将非常困难. 这是因为驱动器数量有限且驱动器切换耗时, 使得为每个生命周期分组维护一盘可立即写入的磁带不可能实现.
4.5 面向磁带的本地存储引擎
在磁带机架内部, TapeOBS 在头节点服务器上运行本地存储引擎. 该存储引擎负责在本地磁带库中持久化存储子 PLog. 图 6 展示了其架构, 由三部分组成: 虚拟数据库(VDB)、磁带库调度器(TLS)和磁带库管理器(TLM). TLM 封装了磁带库的驱动程序: 它可以控制机械臂和磁带驱动器, 以及查询磁带库的状态. 下面介绍 VDB 和 TLS——本地存储引擎中两个面向磁带设计的组件.
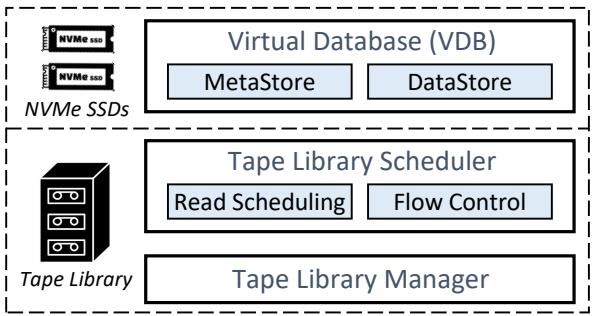
图 6: 面向磁带的本地存储引擎. VDB: 存储子 PLog 的元数据并缓冲数据. TLS: 通过读调度和流量控制优化对磁带的 I/O 请求. TLM: 控制机械臂和磁带驱动器.
4.5.1 虚拟数据库 (VDB)
VDB 利用头节点服务器中的两块 NVMe SSD 创建两个存储区域: MetaStore 和 DataStore.
-
MetaStore. MetaStore 存储磁带机架中所有子 PLog 的元数据. 每个子 PLog 有 256B 的元数据, 包含 plog-id、磁带偏移量、大小、PLog 状态等. 由于 PLog 通常为 GB 级大小, MetaStore 仅需不到 50GB 的 SSD 空间即可维护一个 10PB 磁带库的所有元数据. 通过利用 MetaStore, 我们可以在不触碰磁带的情况下获取子 PLog 的物理位置, 从而避免读取子 PLog 时磁带上的随机元数据访问.
-
DataStore. DataStore 是磁带库上层的持久化缓冲. 对于子 PLog 写入, 数据先缓冲在 DataStore 中, 然后刷入磁带; 子 PLog 读取的方向则相反.
MetaStore 和 DataStore 均以键值存储的形式组织, 具有固定大小的键和值. 对于 MetaStore, 键为 plog-id, 值为子 PLog 元数据. 对于 DataStore, 键为 ⟨plog-id, offset⟩, 值为固定大小的数据切片(如 1MB). 我们利用固定大小 KV 的特性设计了一个简单的键值存储, 如图 7 所示. 该键值存储在 SSD 上预分配两个数组, 即键数组和值数组, 每个元素的大小分别与键和值相同. DRAM 中的一个哈希表维护从键到目标 KV 在数组中索引的映射. 插入 KV 时, 先写入值, 再写入键.
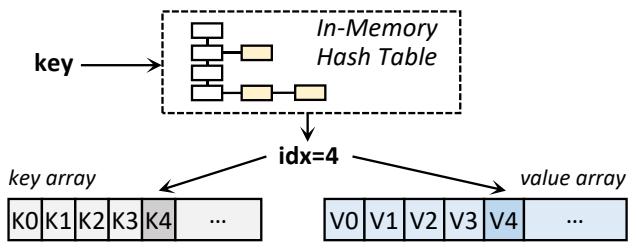
图 7: MetaStore 和 DataStore 使用的基于 SSD 的键值存储. 键数组和值数组存储固定大小的数据. 在崩溃恢复时, 内存中的哈希表可以通过扫描键数组来重建.
该键值存储具有崩溃一致性, 原因如下. 首先, 写入键是原子的, 因为 MetaStore 和 DataStore 中的键均小于 4KB. 其次, 值的完整性可以被验证: 对于 MetaStore, 值为 256B, 因此可以原子写入; 对于 DataStore, 值中每 4KB 数据有一个 DIF(数据完整性字段), 包含 8B 的 plog-id、子 PLog 内的偏移量和 4B 的校验和(已在 §3.3 中提及). 第三, 我们可以检查键和值之间是否匹配, 因为值中存储了关于键的信息. 最后, 在恢复时, 我们可以通过扫描键数组来重建内存中的哈希表.
从 VDB 刷入磁带. 当收到子 PLog 的封存请求时, 头节点服务器中的一个线程将子 PLog 从 VDB 刷入磁带: 1) 从 DataStore 收集属于该子 PLog 的数据切片. DRAM 中为每个子 PLog 维护了一个链表, 连接其数据切片. 2) 该线程通过调用 TLS 将子 PLog 追加到目标磁带(根据 pt-id 确定). 3) 该线程删除 DataStore 中这些数据切片的 KV 对, 并更新 MetaStore 中子 PLog 的元数据(包括磁带偏移量和子 PLog 状态).
磁带中的元数据分区. 我们利用硬件分区特性(回顾 §2.1)在每盘磁带中创建元数据分区. 当一盘磁带写满时, 头节点服务器将关联的子 PLog 元数据从 MetaStore 转储到元数据分区. 元数据分区可以加速 SSD 故障时的恢复: 从磁带的元数据分区重建 MetaStore, 而非扫描磁带中的数据并验证所有 4KB 数据的 DIF.
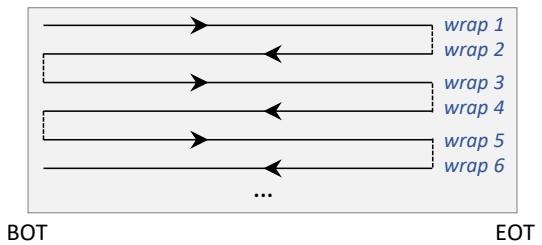
图 8: 一盘现代磁带由数百个磁道组(wrap)组成. BOT: 磁带起始; EOT: 磁带末端.
4.5.2 磁带库调度器 (TLS)
磁带库调度器(TLS)通过读调度和流量控制优化对磁带的数据访问.
读调度. 给定一组包含同一盘磁带中多个子 PLog 的读请求(该组由 DataBrain 发送; 回顾 §4.4), TLS 生成这些子 PLog 的访问顺序, 以减少寻道时间.
一盘现代磁带由数百个磁道组组成; 这些磁道组如图 8 所示被逻辑地连接. 相邻磁道组的访问方向相反, 磁带驱动器必须遵循这些方向. 这种结构使得按逻辑块顺序访问磁带容易产生大量不必要的寻道. TLS 采用简单的 SCAN 算法来优化一组子 PLog 的访问: 1) 对于每个子 PLog, TLS 计算其在磁带上的物理位置. 注意我们预先维护了磁带逻辑块与物理位置之间的映射关系. 2) TLS 根据子 PLog 所在磁道组的访问方向, 将子 PLog 分为两个队列. 3) TLS 按物理位置对每个队列中的子 PLog 排序. 4) TLS 先执行一个队列中的请求, 再执行另一个队列中的请求.
流量控制. 在部署 TapeOBS 期间, 我们发现了磁带驱动器上频繁出现的性能异常. 图 9(a) 展示了这样一个案例, 我们采集了一个写驱动器在 15 分钟内的带宽数据. 在前 79 秒, 驱动器性能稳定: 平均 335.94MB/s, 接近 360MB/s 的理论性能上限. 在接下来的 48 秒中, 驱动器性能经历了严重波动. 随后, 带宽下降至一半, 平均 168.65MB/s; 此过程持续 285 秒.
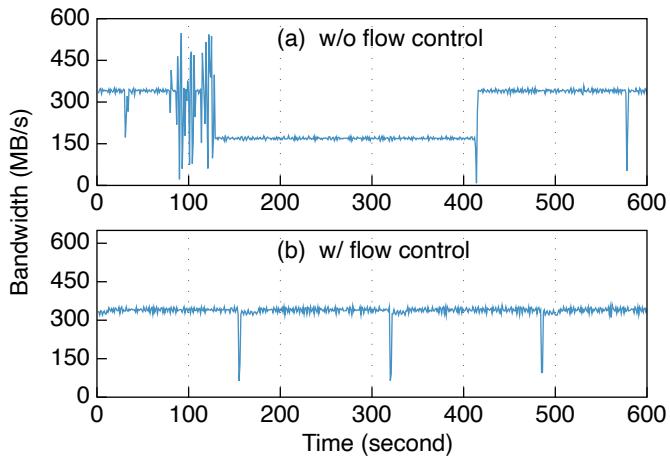
图 9: 写驱动器的带宽. (a): TLS 在无流量控制的情况下向驱动器提交请求: 在 129s∼414s 期间出现性能下降. (b): TLS 使用流量控制向驱动器提交请求: 带宽稳定, 平均为 336.53MB/s.
经分析, 我们认为原因在于不稳定的 I/O 请求提交速率. 磁带驱动器中有一个缓冲区, 用于吸收来自主机的数据. 驱动器以恒定速度(从一组预定义速度中选择)将缓冲区中的数据写入磁带; 驱动器通过内部算法选择速度. 然而, 当 TLS 以高度抖动的方式提交请求时(即图 9(a) 中 ), 驱动器可能错误地估计主机速度并选择较低的速度, 从而导致性能下降.
我们使用流量控制来解决此问题. 其核心思想是将请求提交速度与驱动器速度对齐. TLS 定期读取驱动器缓冲区的大小, 并用其估算驱动器速度(我们称之为 DS). TLS 将请求发送到一个速率限制器, 由其将请求提交速度调整为 DS. 如果待提交数据不足 100MB, TLS 绕过速率限制器. 这样可以避免驱动器选择不匹配的速度. 图 9(b) 展示了应用流量控制后写驱动器的带宽. 写驱动器提供了稳定的带宽(平均 336.53MB/s). 需要注意的是, 大约每 163 秒, 性能会出现 1-2 秒的陡降, 这是因为驱动器磁头正在通过改变方向切换到新的磁道组(回顾图 8 中的磁带结构).
5 TapeOBS 的部署
TapeOBS 于 2022 年底开始灰度发布, 并于 2024 年正式对外服务客户. 目前, TapeOBS 是一个单可用区服务, 部署在多个集群上, 每个集群由多个磁带池组成. 需要注意的是, 同一集群中的不同磁带池可以共享一个服务层、一个索引层和一个 DataBrain; 但每个磁带池拥有专用的 MDC 来管理分区, 这意味着磁带池是基本部署单元. 每个磁带池配备 14 个磁带机架, 总容量为 140PB. TapeOBS 使用 的纠删码配置, 存储冗余为 1.17. 经 EC 编码的数据——包含 12 个数据块和 2 个校验块——分布在 14 个磁带机架上. 截至撰稿时, TapeOBS 已存储了数百 PB 的原始用户数据24.
本节我们首先分析对象大小的分布(§5.1)和对象操作的比例(§5.2), 两者均呈现高度偏斜的模式. 然后, 我们选择一个代表性集群来展示其指标, 如容量利用率和性能(§5.3, §5.4 和 §5.5). 最后, 我们展示 TapeOBS 部署中磁带库的故障特征(§5.6).
5.1 对象大小分布
我们收集了 TapeOBS 中存储对象大小的统计数据. 图 10 展示了累积分布函数(CDF), 其中 x 轴表示对象大小, y 轴表示小于或等于该大小的对象占 TapeOBS 总存储容量的累积比例. 从图中可以清晰地观察到: 对象大小呈现高度偏斜的模式. 具体而言, 小于 500MB 的对象占 TapeOBS 存储空间的 ; 其中, 为 50-100MB 范围内的对象.
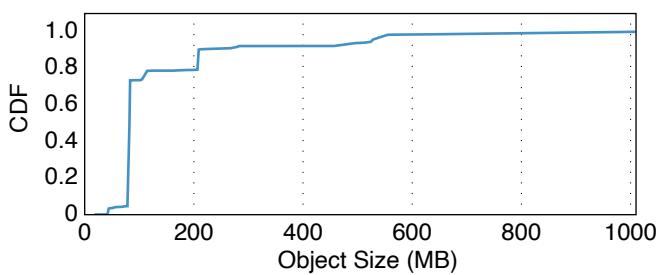
图 10: TapeOBS 中对象大小分布的 CDF. 对象大小呈现高度偏斜的模式.
我们还分析了 TapeOBS 最大客户的全部 44 个桶, 计算每个桶的平均对象大小及其占该客户总存储容量的比例, 如图 11 所示. 其中, 三个桶的容量占比超过 : 一个平均对象大小为 81.92MB 的桶占总容量的 , 另一个平均对象大小为 83.19MB 的桶占 , 第三个平均对象大小为 208.90MB 的桶占 . GB 级别的大对象相对较少: 仅有一个桶的平均对象大小超过 1000MB, 为 1009.3MB; 它占总容量的 .
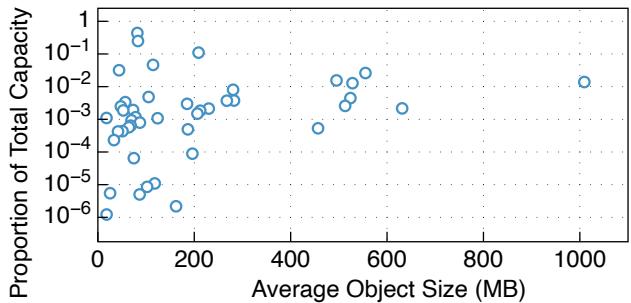
图 11: 各桶的平均对象大小 vs. 容量占比. 每个点代表一个桶. x 轴表示该桶的平均对象大小(MB), y 轴表示该桶占总存储容量的比例.
5.2 对象操作比例
表 4 展示了 TapeOBS 五大客户(按存储容量从 A 到 E 降序排列, A 为最大客户)的对象级操作(写入、读取和删除)比例. 从表中可以得出两个观察结论.
首先, 归档工作负载以写操作为绝对主导, 而读操作极为罕见. 客户 B 的读取比例最高, 但即便如此, 读操作也仅占其总操作的 . 对于最大客户 A, 读取比例更为边际, 仅 . 客户 D 和 E 未发起任何读请求, 凸显了归档数据的典型访问模式: 以写为主, 几乎无读.
其次, 删除操作同样非常少见. 仅客户 E 发起过删除请求, 占其总操作的 . 这是因为在 TapeOBS 中, 归档对象通常在到期时自动删除, 而非由用户显式执行删除操作.
| 客户 | 写入 | 读取 | 删除 |
|---|---|---|---|
| A | 99.999888% | 0.000112% | 0% |
| B | 99.325224% | 0.674776% | 0% |
| C | 99.999872% | 0.000128% | 0% |
| D | 100% | 0% | 0% |
| E | 99.986719% | 0% | 0.013281% |
表 4: 不同操作的比例. 我们选取了五个最大客户, 按数据量从 A 到 E 降序排列, 客户 A 为最大客户.
5.3 HDD 池和磁带池的利用率
我们选取 TapeOBS 中一个活跃集群, 统计了磁带池和 HDD 池在 24 小时内(即一天)的空间利用率. 图 12 展示了结果. 需要注意的是, 对于磁带池, 我们展示的是数据增长量, 并以 HDD 池总容量的百分比表示. 从图 12(a) 可以观察到, HDD 池的利用率在 至 之间波动. 在 TapeOBS 中, HDD 池是一个暂存区, 用于支撑完全异步的磁带池. HDD 池中的数据在以下情况下增加: 1) 用户提交写请求; 2) TapeOBS 将数据从磁带池复制到 HDD 池以服务恢复请求. 相反, 当 TapeOBS 执行批量数据调度, 将对象从 HDD 池移至磁带池时, HDD 池中的数据减少. 从图 12(b) 可以观察到, TapeOBS 以相对恒定的速率将数据从 HDD 池消化到磁带池.
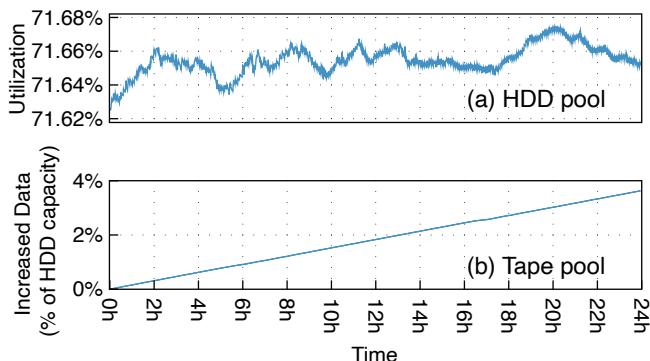
图 12: HDD 池和磁带池的容量利用率. 注意对于磁带池, 我们展示的是数据增长量, 并以 HDD 池总容量的百分比表示.
目前, 我们为 HDD 池设置了 的容量水位线: 通过控制数据移至磁带的速度, 确保 HDD 容量不超过此水位线. 我们保留 的 HDD 空间, 基于以下三个原因. 首先, 余量可以吸收用户触发的不可预测的突发流量. 其次, 该空间可用于 HDD 池的内部活动, 如 HDD 故障时的 EC 修复. 最后, 这可以避免由于过度利用导致的 HDD 性能下降.
5.4 HDD 池和磁带池的吞吐量
我们采集了 HDD 池和磁带池在 24 小时内(与 §5.3 同一时段)的实时吞吐量. 图 13 展示了结果. 需要注意的是, 我们的性能采集工具统计的是 PLog-Client 执行的写入/读取 EC 条带的次数, 而非 PLog 接口的调用次数. 在 TapeOBS 生产环境中, 一个条带由 12 个 512KB 数据块和 2 个 512KB 校验块组成25. 换言之, 在图中, 一次追加操作写入一个 的条带(即 7MB); 一次读取操作读取 的数据(即 6MB).
如图 13(a) 所示, 在 24 小时内, 磁带池的写入吞吐量介于 39.67Kops/min 至 148.79Kops/min 之间, 平均值为 118.81Kops/min(即 ). 尽管写入吞吐量存在抖动, 但按小时累计时, 可以发现每小时的累计写入量相对稳定: 除第 6 小时(6162.69Kops/h)和第 17 小时(5451.34Kops/h)外, 其余 22 小时的吞吐量介于 7052.58Kops/h 至 7469.22Kops/h 之间. 这与图 12(a) 一致, 后者表明磁带池以相对恒定的速率增加数据(第 17 小时可以在图中更仔细地观察到一个轻微的下降斜率). 与写入不同, 磁带池的读取吞吐量较低: 在此 24 小时内最高为每分钟 5.85K 次操作. 这也表明在我们的归档工作负载中, 用户的恢复请求较少.
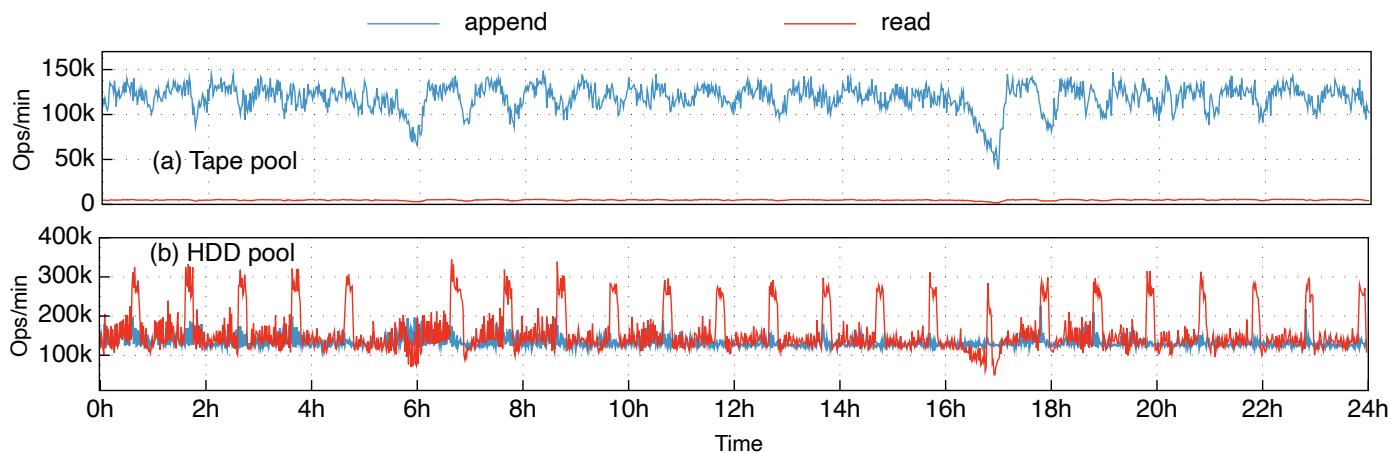
图 13: 磁带池和 HDD 池 24 小时内的吞吐量. 在本图中, 一次追加操作写入一个 的条带(即 7MB); 一次读取操作读取 的数据(即 6MB).
从图 13(b) 可以得出两个观察结论. 首先, HDD 池的平均写入和读取吞吐量分别为 134.015Kops/min 和 158.139Kops/min. 写入吞吐量主要反映了用户提交写请求的速度(回顾: 恢复请求很少). 读取吞吐量主要反映了 TapeOBS 将数据移至磁带池的速度.
其次, HDD 池的读取吞吐量高于磁带池的写入吞吐量, 这是因为 HDD 池在后台执行垃圾回收(GC), 产生了额外的读写. 与磁带池类似, HDD 池使用仅追加的 PLog 作为存储单元. 由于 TapeOBS 使用基于生命周期的聚合方式将对象从 HDD 移至磁带, HDD 池中存在大量包含垃圾数据的 PLog. 为确保 HDD 池利用率低于 (回顾 §5.3), TapeOBS 执行 GC: 服务层从旧 PLog 中读取有效对象, 将其写入新 PLog, 并删除旧 PLog. 如图 13(b) 所示, HDD 池的 GC 周期性触发, 导致读取吞吐量出现周期性峰值. 在 GC 期间, 新 PLog 以稳定速率写入 HDD 池. 磁带池中没有显著的 GC 流量, 这是因为通过基于生命周期的放置, 在大多数情况下我们可以直接删除一个 EC 组中的所有数据.
5.5 磁带池的写入延迟
TapeOBS 采用面向磁带的本地存储引擎, 利用本地 SSD 持久化缓冲数据和元数据. 因此, 当所有数据块和校验块到达各关联磁带机架中 SSD 上的 DataStore 时, 磁带池的写操作即完成. 我们采集了向磁带池写入一个条带的延迟, 图 14 展示了延迟 CDF. 中位延迟和 P99 延迟分别为 18.51ms 和 27.75ms. 网络约消耗 10ms 延迟, 因为 TapeOBS 使用的是内核级 TCP/IP 网络栈. DataStore 约消耗 1-4ms 用于将数据和元数据写入 SSD. 其余时间耗费在服务层 PLog-Client 的软件逻辑上, 包括计算 EC 校验块、为每 4KB 生成校验和以及内存拷贝.
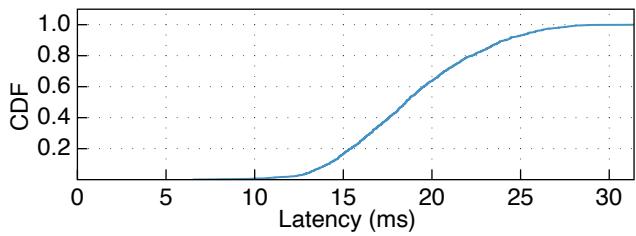
图 14: 写入延迟的 CDF. 一次操作写入一个 的条带(即 7MB).
5.6 磁带库的故障特征
在 TapeOBS 的部署和运营过程中, 我们共记录了 17 次与磁带库相关的故障. 这些统计数据收集自 2024 年正式上线面客运营以来约 1.25 年的时间段. 我们当前的部署规模不到 200 个磁带库, 这一数量受到每个磁带库 10PB 高存储密度的影响. 表 5 详细列出了这些故障及其各自的比例.
| ID | 故障类型 | 比例 |
|---|---|---|
| 1 | 驱动器软件缺陷 | 4/17 |
| 2 | 驱动器故障 | 4/17 |
| 3 | 驱动器无法识别磁带 | 4/17 |
| 4 | 驱动器未找到 | 1/17 |
| 5 | 机械臂卡住 | 2/17 |
| 6 | 头节点服务器与磁带库断连 | 2/17 |
表 5: 磁带库的故障特征. 此处聚焦于磁带库相关的故障, 而非网络问题和存储设备故障(如 SSD 和磁带)等其他类型.
对于驱动器软件缺陷(❶), 我们遇到了某些驱动器在执行过程中出现异常性能下降的情况, 这不影响系统的可用性, 但需要更新驱动器软件.
当驱动器无法工作时(❷❸❹), TapeOBS 根据驱动器执行的任务产生不同的后果. 回顾 TapeOBS 将磁带库中的驱动器静态划分为三组(§4.2): 2 个写驱动器、1 个读驱动器和 1 个内部驱动器. 当故障驱动器为写驱动器时, 磁带池的写入吞吐量将下降. 当故障驱动器为读驱动器时, 关联机架中的对象恢复将转换为从其他磁带机架进行降级读. 当故障驱动器为内部驱动器时, 磁带池性能不受影响, 内部操作需等待运维人员介入(如安装新驱动器)后恢复.
在某些情况下, 整个磁带库可能无法运作, 例如机械臂卡住(❺)或头节点服务器与磁带库断连(❻). 此时, 磁带池无法执行写操作, 并使用降级读来服务读操作. 但 TapeOBS 仍可处理用户的写请求: HDD 池将使用其 的未用空间来吸收写入, 这可以额外支撑数十小时(回顾图 12(b), 24 小时内的用户写入量不到 HDD 池容量的 ), 为运维人员提供充足的时间修复磁带库.
6 相关工作
我们从两个方面考察相关工作, 包括基于磁带的存储系统和其他归档存储系统.
6.1 基于磁带的存储系统
有兴趣的读者可参阅 IBM 的一篇最新文章8, 该文从硬件到软件详细介绍了现代磁带. LTFS13和 HTPFS26是为磁带设计的文件系统. LTFS 利用硬件分区创建元数据区域, 并以 XML 格式索引存储元数据. bLTFS27通过空间高效的二进制索引增强了 LTFS. TapeOBS 在磁带中存储子 PLog, 并使用元数据分区加速恢复. GLUFS28将 LTFS 集成到分布式文件系统 GPFS 中, 根据数据热度在磁盘和磁带之间迁移数据. TapeOBS 包含一个用于批量调度和对象恢复的 HDD 池. CloudDT29和 DeduT30为磁带库设计了数据去重方案; TapeOBS 目前不支持去重.
部分工作探索了通过重排序请求来减少磁带寻道时间的算法31323334. 先进的算法32同时考虑了纵向维度(即块之间的物理距离)和横向维度(即磁道组之间的切换)的开销. TapeOBS 的 SCAN 算法仅从纵向维度进行优化, 并以子 PLog 为基本单元. Quantum 为磁带采用了一种称为二维纠删码(two-dimensional EC)[^ref2]的 EC 方案, 使用磁带间(inter-tape)和磁带内(intra-tape)EC 来保护数据. TapeOBS 将磁带视为基本故障单元, 不考虑磁带的部分故障.
6.2 其他归档存储系统
除磁带外, HDD3521、玻璃介质(glass)3637、蓝光光盘(Blu-Ray disk)[^1a]和 DNA3839404142等介质也被用于构建归档存储系统. 阿里巴巴利用 HM-SMR HDD 构建归档级对象存储21. 微软的 Silica 项目将归档数据保存在石英玻璃(quartz glass)中36, 可提供超过 1000 年的使用寿命. Meta 使用蓝光光盘存储其社交媒体平台上的冷照片[^1a]. DNA 提供了超高密度、长期归档存储的潜力, 但写入速度慢和技术复杂性等挑战仍需克服3941. 最近, Brunmayr 等人设计了一种生成 DNA 基序(motif)的方法38, 以实现更快、更经济的 DNA 合成; Zhou 等人提出了一种 DNA 块设备, 使用 SSD 降低元数据更新成本42.
7 结论
我们描述了理解、设计和部署 TapeOBS 的历程——一种华为云上基于磁带的归档存储服务. TapeOBS 基于三个设计原则构建: 1) 使对磁带池的读写异步化; 2) 最小化磁带库内的驱动器抖动; 3) 避免磁带内的随机读取. TapeOBS 为基于云的归档存储提供了高性价比的解决方案, 已存储了数百 PB 的原始用户数据
References
-
Amount of Data Created Daily (2024). https://explodingtopics.com/blog/data-generated-per-day, 2024. ↩︎
-
Huawei Cloud – Object Storage Service (OBS). https://www.huaweicloud.com/intl/en-us/product/obs.html, 2025. ↩︎ ↩︎ ↩︎
-
Amazon S3 Glacier storage classes. https://aws.amazon.com/s3/storage-classes/glacier/, 2025. ↩︎ ↩︎
-
Google Cloud – Archive storage. https://cloud.google.com/storage/docs/storage-classes#archive, 2025. ↩︎ ↩︎
-
Alibaba Cloud – Object Storage Service. https://www.alibabacloud.com/en/product/object-storage-service, 2025. ↩︎ ↩︎
-
Overland-Tandberg. Tape Sustainability – The new future of magnetic tape storage. https://www.also.com/ec/cms5/media/documents/1010_central_1/pdf_16/wp_neo_tape_sustainability_emea.pdf, 2023. ↩︎ ↩︎
-
Information Storage Industry Consortium. NSIC International Magnetic Tape Storage Technology Roadmap 2024. https://insic.org/wp-content/uploads/2024/08/INSIC-International-Magnetic-Tape-Storage-Technology-Roadmap-2024-1.pdf, 2024. ↩︎ ↩︎
-
Mark A. Lantz, Simeon Furrer, Martin Petermann, Hugo Rothuizen, Stella Brach, Luzius Kronig, Ilias Iliadis, Beat Weiss, Ed R. Childers, and David Pease. Magnetic Tape Storage Technology. ACM Trans. Storage, 21(1), January 2025. ↩︎ ↩︎
-
本文中 “磁带盒” 与 “磁带” 可互换使用. ↩︎
-
Linear Tape-Open. https://www.lto.org/, 2025. ↩︎
-
G. A. Jaquette. LTO: A better format for mid-range tape. IBM Journal of Research and Development, 47(4):429–444, 2003. ↩︎ ↩︎
-
IBM 3592 Tape Cartridge. https://www.ibm.com/products/3592-tape-cartridge, 2025. ↩︎
-
David Pease, Arnon Amir, Lucas Villa Real, Brian Biskeborn, Michael Richmond, and Atsushi Abe. The Linear Tape File System. In 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), pages 1–8, 2010. ↩︎ ↩︎
-
Weiping He and David H.C. Du. SMaRT: An Approach to Shingled Magnetic Recording Translation. In 15th USENIX Conference on File and Storage Technologies (FAST 17), pages 121–134, Santa Clara, CA, February 2017. USENIX Association. ↩︎
-
IBM Diamondback Tape Library. https://www.ibm.com/products/diamondback-tape-library, 2025. ↩︎
-
Patrick Hunt, Mahadev Konar, Flavio P. Junqueira, and Benjamin Reed. ZooKeeper: Wait-free Coordination for Internet-scale Systems. In 2010 USENIX Annual Technical Conference (USENIX ATC 10). USENIX Association, June 2010. ↩︎
-
为简化起见, 我们将 PLog 中驻留在单个磁带上的每个部分称为子 PLog(sub-PLog). ↩︎
-
David F. Bacon. Detection and Prevention of Silent Data Corruption in an Exabyte-scale Database System. In The 18th IEEE Workshop on Silicon Errors in Logic – System Effects, 2022. ↩︎
-
Brad Calder, Ju Wang, Aaron Ogus, Niranjan Nilakantan, Arild Skjolsvold, Sam McKelvie, Yikang Xu, Shashwat Srivastav, Jiesheng Wu, Huseyin Simitci, Jaidev Haridas, Chakravarthy Uddaraju, Hemal Khatri, Andrew Edwards, Vaman Bedekar, Shane Mainali, Rafay Abbasi, Arpit Agarwal, Mian Fahim ul Haq, Muhammad Ikram ul Haq, Deepali Bhardwaj, Sowmya Dayanand, Anitha Adusumilli, Marvin McNett, Sriram Sankaran, Kavitha Manivannan, and Leonidas Rigas. Windows Azure Storage: a highly available cloud storage service with strong consistency. In Proceedings of the Twenty-Third ACM Symposium on Operating Systems Principles, SOSP ‘11, page 143–157, New York, NY, USA, 2011. Association for Computing Machinery. ↩︎
-
Satadru Pan, Theano Stavrinos, Yunqiao Zhang, Atul Sikaria, Pavel Zakharov, Abhinav Sharma, Shiva Shankar P, Mike Shuey, Richard Wareing, Monika Gangapuram, Guanglei Cao, Christian Preseau, Pratap Singh, Kestutis Patiejunas, JR Tipton, Ethan Katz-Bassett, and Wyatt Lloyd. Facebook’s Tectonic Filesystem: Efficiency from Exascale. In 19th USENIX Conference on File and Storage Technologies (FAST 21), pages 217–231. USENIX Association, February 2021. ↩︎
-
Su Zhou, Erci Xu, Hao Wu, Yu Du, Jiacheng Cui, Wanyu Fu, Chang Liu, Yingni Wang, Wenbo Wang, Shouqu Sun, Xianfei Wang, Bo Feng, Biyun Zhu, Xin Tong, Weikang Kong, Linyan Liu, Zhongjie Wu, Jinbo Wu, Qingchao Luo, and Jiesheng Wu. SMRSTORE: A Storage Engine for Cloud Object Storage on HM-SMR Drives. In 21st USENIX Conference on File and Storage Technologies (FAST 23), pages 395–408, Santa Clara, CA, February 2023. USENIX Association. ↩︎ ↩︎ ↩︎
-
Harish Dixit. Keytone: Silent data corruptions at scale. In 2023 IEEE 29th International Symposium on On-Line Testing and Robust System Design (IOLTS), pages 1–2, 2023. ↩︎
-
Shaobu Wang, Guangyan Zhang, Junyu Wei, Yang Wang, Jiesheng Wu, and Qingchao Luo. Understanding Silent Data Corruptions in a Large Production CPU Population. In Proceedings of the 29th Symposium on Operating Systems Principles, SOSP ‘23, page 216–230, New York, NY, USA, 2023. Association for Computing Machinery. ↩︎
-
出于商业原因, 我们无法公开 TapeOBS 的确切存储容量. ↩︎
-
对于 PLog 追加/读取, PLog-Client 以条带为单位向磁带池和 HDD 池写入/读取数据. ↩︎
-
Xianbo Zhang, David Du, Jim Hughes, Ravi Kavuri, and Sun StorageTek. Hptfs: A high performance tape file system. In Proceedings of 14th NASA Goddard/23rd IEEE conference on Mass Storage System and Technologies. Citeseer, 2006. ↩︎
-
Klaus Birkelund Jensen and Brian Vinter. Binary index and journal embedding in the linear tape file system. In 2017 International Conference on Networking, Architecture, and Storage (NAS), pages 1–7, 2017. ↩︎
-
Ioannis Koltsidas, Slavisa Sarafijanovic, Martin Petermann, Nils Haustein, Harald Seipp, Robert Haas, Jens Jelitto, Thomas Weigold, Edwin Childers, David Pease, and Evangelos Eleftheriou. Seamlessly integrating disk and tape in a multi-tiered distributed file system. In 2015 IEEE 31st International Conference on Data Engineering, pages 1328–1339, 2015. ↩︎
-
Abdullah Gharaibeh, Cornel Constantinescu, Maohua Lu, Anurag Sharma, Ramani R Routray, Prasenjit Sarkar, David Pease, and Matei Ripeanu. Clouddt: Efficient tape resource management using deduplication in cloud backup and archival services. In 2012 8th international conference on network and service management (cnsm) and 2012 workshop on systems virtualiztion management (svm), pages 169–173, 2012. ↩︎
-
Abdullah Gharaibeh, Cornel Constantinescu, Maohua Lu, Ramani Routray, Anurag Sharma, Prasenjit Sarkar, David Pease, and Matei Ripeanu. Dedupt: Deduplication for tape systems. In 2014 30th Symposium on Mass Storage Systems and Technologies (MSST), pages 1–11, 2014. ↩︎
-
Carlos Cardonha and Lucas Villa Real. Online algorithms for the linear tape scheduling problem. In Proceedings of the International Conference on Automated Planning and Scheduling, volume 26, pages 70–78, 2016. ↩︎
-
Valentin Honoré, Bertrand Simon, and Frédéric Suter. An exact algorithm for the linear tape scheduling problem. In Proceedings of the International Conference on Automated Planning and Scheduling, volume 32, pages 151–159, 2022. ↩︎ ↩︎
-
O. Sandsta and R. Midtstraum. Analysis of retrieval of multimedia data stored on magnetic tape. In Proceedings International Workshop on Multi-Media Database Management Systems (Cat. No.98TB100249), pages 54–63, 1998. ↩︎
-
O. Sandsta and R. Midtstraum. Low-cost access time model for serpentine tape drives. In 16th IEEE Symposium on Mass Storage Systems in cooperation with the 7th NASA Goddard Conference on Mass Storage Systems and Technologies (Cat. No.99CB37098), pages 116–127, 1999. ↩︎
-
Shobana Balakrishnan, Richard Black, Austin Donnelly, Paul England, Adam Glass, Dave Harper, Sergey Legtchenko, Aaron Ogus, Eric Peterson, and Antony Rowstron. Pelican: A Building Block for Exascale Cold Data Storage. In 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI 14), pages 351–365, Broomfield, CO, October 2014. USENIX Association. ↩︎
-
Patrick Anderson, Erika Blancada Aranas, Youssef Assaf, Raphael Behrendt, Richard Black, Marco Caballero, Pashmina Cameron, Burcu Canakci, Thales De Carvalho, Andromachi Chatzieleftheriou, Rebekah Storan Clarke, James Clegg, Daniel Cletheroe, Bridgette Cooper, Tim Deegan, Austin Donnelly, Rokas Drevinskas, Alexander Gaunt, Christos Gkantsidis, Ariel Gomez Diaz, Istvan Haller, Freddie Hong, Teodora Ilieva, Shashidhar Joshi, Russell Joyce, Mint Kunkel, David Lara, Sergey Legtchenko, Fanglin Linda Liu, Bruno Magalhaes, Alana Marzoev, Marvin Mcnett, Jayashree Mohan, Michael Myrah, Trong Nguyen, Sebastian Nowozin, Aaron Ogus, Hiske Overweg, Antony Rowstron, Maneesh Sah, Masaaki Sakakura, Peter Scholtz, Nina Schreiner, Omer Sella, Adam Smith, Ioan Stefanovici, David Sweeney, Benn Thomsen, Govert Verkes, Phil Wainman, Jonathan Westcott, Luke Weston, Charles Whittaker, Pablo Wilke Berenguer, Hugh Williams, Thomas Winkler, and Stefan Winzeck. Project Silica: Towards Sustainable Cloud Archival Storage in Glass. In Proceedings of the 29th Symposium on Operating Systems Principles, SOSP ‘23, page 166–181, New York, NY, USA, 2023. ACM. ↩︎ ↩︎
-
Patrick Anderson, Richard Black, Ausra Cerkauskaite, Andromachi Chatzieleftheriou, James Clegg, Chris Dainty, Raluca Diaconu, Rokas Drevinskas, Austin Donnelly, Alexander L. Gaunt, Andreas Georgiou, Ariel Gomez Diaz, Peter G. Kazansky, David Lara, Sergey Legtchenko, Sebastian Nowozin, Aaron Ogus, Douglas Phillips, Antony Rowstron, Masaaki Sakakura, Ioan Stefanovici, Benn Thomsen, Lei Wang, Hugh Williams, and Mengyang Yang. Glass: A New Media for a New Era? In 10th USENIX Workshop on Hot Topics in Storage and File Systems (HotStorage 18), Boston, MA, July 2018. USENIX Association. ↩︎
-
Samira Brunmayr, Omer S. Sella, and Thomas Heinis. DNA data storage: A generative tool for motif-based DNA storage. In 23rd USENIX Conference on File and Storage Technologies (FAST 25), pages 573–581, Santa Clara, CA, February 2025. USENIX Association. ↩︎ ↩︎
-
Bingzhe Li, Nae Young Song, Li Ou, and David H.C. Du. Can we store the whole world’s data in dna storage? In Proceedings of the 12th USENIX Conference on Hot Topics in Storage and File Systems, HotStorage ‘20, USA, 2020. USENIX Association. ↩︎ ↩︎
-
Jiwu Shu. Data Storage Architectures and Technologies. Springer, 2024. ↩︎
-
Christopher N. Takahashi, David P. Ward, Carlo Cazzaniga, Christopher D. Frost, Paolo Rech, Kumkum Ganguly, Sean Blanchard, Steve Wender, Bichlien Nguyen, and Jake Smith. Evaluating the risk of data loss due to particle radiation damage in a dna data storage system. Nature Communications, 15:8067, September 2024. ↩︎ ↩︎
-
Jiahao Zhou, Mingkai Dong, Fei Wang, Jingyao Zeng, Lei Zhao, Chunhai Fan, and Haibo Chen. Liquid-State drive: A case for DNA block device for enormous data. In 23rd USENIX Conference on File and Storage Technologies (FAST 25), pages 557–571, Santa Clara, CA, February 2025. USENIX Association. ↩︎ ↩︎